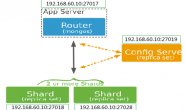
1)配置集群
启动shard节点
一个shard节点可以是一个单独的mongod或者是一个replica set。在生产环境中,每个分片都应该是一个复制集。参见部署复制集将每个分片部署为复制集。
|
1 |
mongod --shardsvr --fork --port <port> --logpath <path> --logappend --dbpath <path> --pidfilepath <path> |
启动config server节点
配置服务器必须开启1个(会有警告)或则3个,开启2个则会报错。另外从MongoDB3.2开始,config servers可以部署为一个复制集,但这个复制集中的config server节点必须是WiredTiger存储引擎。
|
1 |
mongod --configsvr --fork --port <port> --logpath <path> --logappend --dbpath <path> --pidfilepath <path> |
Mongodb3.2支持复制集Config Server,其配置也非常简单,先在三个Config Server节点上配置复制集及config server,基本参数如下:
|
1 2 3 4 5 6 |
###Replica Set oplogSize = 1024 replSet = ywnds ###Config Server configsvr = true |
然后连接到一个mongo shell开始使用rs.initiate方式初始化复制集即可。
|
1 2 3 4 5 6 7 8 9 |
rs.initiate( { _id: "configReplSet", configsvr: true, members: [ { _id: 0, host: "<host1>:<port1>" }, { _id: 1, host: "<host2>:<port2>" }, { _id: 2, host: "<host3>:<port3>" } ] } ) |
启动mongos节点
mongos实例是轻量服务,并且不需要数据目录,所以只需要记录一下日志即可。你可以将 mongos 运行在已经部署了其他服务的系统中,比如应用服务器或者运行了mongod的机器上,默认运行在 27017 端口上。
对于非复制集Config Server,mongos启动语法:
|
1 |
mongos --configdb <cfgsvr1:port1> --fork --port <port> --logpath <path> --logappend --pidfilepath <path> |
#Mongos节点指定配置服务器地址,但必须是1个或则3个配置服务器
对于复制集Config Server,mongos启动语法:
|
1 |
mongos --configdb configReplSet/<cfgsvr1:port1>,<cfgsvr2:port2>,<cfgsvr3:port3> --fork --port <port> --logpath <path> --logappend --pidfilepath <path> |
2)向集群中添加分片
步骤一、连接到mongos
|
1 |
mongo --host <hostname of machine running mongos> --port <port mongos listens on> |
步骤二、Add Shard(操作对象有单个数据库实例和复制集两种)
添加shard可以使用数据库命令添加也可以使用sh.addShard()方法添加。下面是使用 sh.addShard() 添加分片的例子:假设一个分片使用了复制集,复制集名字为ywnds,有一个mongodb0.example.net且端口为27017的成员,使用以下命令添加这个分片:
|
1 |
sh.addShard( "ywnds/mongodb0.example.net:27017" ) |
添加mongodb0.example.net端口为27017的单机mongod分片,需要执行以下命令:
|
1 |
sh.addShard( "mongodb0.example.net:27017" ) |
步骤三、为集群数据库开启分片
在对集合进行分片之前,必须开启数据库的分片。对数据库开启分片不会导致数据的重新分配,但这是对这个数据库中集合进行分片的前提。一旦为数据库开启了分片,MongoDB就会为这个数据库指定一个primary shard,所有未分片的数据都会存储在这个分片上。
使用sh.enableSharding()需要指定要开启分片的数据的名字,语法如下:
|
1 |
sh.enableSharding("<database>") |
你也可以使用enableSharding命令对数据库开启分片,语法如下:
|
1 |
db.runCommand( { enableSharding: <database> } ) |
步骤四、对一个集合进行分片
1.如果集合中已经包含有数据,需要使用db.collection.ensureIndex()在片键上创建索引。如果集合是空的,MongoDB会在sh.shardCollection()过程中自动创建索引。
2.首先选择一个片键(shard key),选择片键的好坏很大程度上影响集群的性能,容量和功能。
3.使用mongo shell的sh.shardCollection()方法对集合进行分片,语法如下:
|
1 |
sh.shardCollection("<database>.<collection>", shard-key-pattern) |
将<database>.<collection>字符串换成你数据库的ns。由数据库的全名,一个点(即 . ),和集合的全名组成,hard-key-pattern换成你的片键,名字为创建索引时指定的名字。如下示例:
|
1 2 3 |
sh.shardCollection("records.people", { "zipcode": 1, "name": 1 } ) sh.shardCollection("people.addresses", { "state": 1, "_id": 1 } ) sh.shardCollection("events.alerts", { "_id": "hashed" } ) |
按照顺序解释(前两种都属于基于范围分片,后一种属于基于哈希分片):
a) records数据库中的people集合使用{ “zipcode”: 1, “name”: 1 }片键开启分片.
这个集合使用zipcode字段作为重新分配数据块的片键(1表示索引升序),如果很多文档都有相同的zipcode值,那么Chunk会按照name片键的值进行分裂。
b) people数据库中的addresses集合使用片键{ “state”: 1, “_id”: 1 }.
这个集合使用state字段作为重新分配数据块的片键,如果很多文档都有相同的state值,那么Chunk会按照_id片键的值进行分裂。
c) events数据库中的alerts集合使用{ “_id”: “hashed” }做片键.
这个集合使用state字段作为重新分配数据块的片键,MongoDB为散列索引计算_id的值,可以保证集群中数据的均衡。MongDB从2.4版本开始支持基于哈希的分片了。分片过程中利用哈希索引作为分片的单个键,且哈希分片的片键只能使用一个字段,而基于哈希片键最大的好处就是保证数据在各个节点分布基本均匀。对于基于哈希的分片,MongoDB计算一个字段的哈希值,并用这个哈希值来创建数据块。在使用基于哈希分片的系统中,拥有”相近”片键的文档很可能不会存储在同一个数据块中,因此数据的分离性更好一些。
如何选择一个合适的片键?
一些人并不能真正理解或者信任MongoDB自动分配数据的方式,数据的分配方式是根据片键而决定的,所以一个集合中片键的设计非常重要。下面我们看一看几个比较坑的片键设计方式,然后对比着好的片键设计,让我们能够真正理解片键设计对分片的影响。
第一种:小基数片键
一个小基数片键的设计会带来的问题就是数据块持续增长,容易形成大的数据块,导致数据分片的不均衡以及数据块持续变大。一般由于片键值数量有限,我们称之为小基数片键(low-cardinality shard key)。下面用实例说说为什么小基数片键会导致数据块持续变大?
实例:Apache日志
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ node: "ywnds.com", application: "apache", time: " 18/Feb/2016:15:09:15 +0800", level: "ERROR",msg: "something is broken" } { node: "sdnwy.com", application: "apache", time: " 18/Feb/2016:15:09:15 +0800", level: "ERROR",msg: "something is broken" } |
对于上面这样两个虚拟主机访问日志的存储分片,如果我们选用“node:1”字段作为片键的话。集合开始于某一个分片的初始块上,所有的插入和读取都落在这一个块上。一旦它变得足够大时,就会被划分成两个块根据这两个“ywnds.com”,“sdnwy.com”不同的主机名(如果有第三个主机名的话,就会以中间的那个主机名为区间进行划分)。
然后随着更多日志文档被添加进来,那么每条日志node字段的值无非就是这两个主机名,也就是说片键不会发生变化,集合最终也就变成2个块。MongoDB无法再根据node进行分割这些块了!那么块只能变得越来越大(块默认大小64MB),当磁盘空间出现问题时除了买容量更大的磁盘,你什么也做不了。
这个规则使用于任何取值个数有限的键,所以,如果在某集合中一个键有N个值,那就只能有N个数据块,因此也只能有N个分片。那么比较适合的片键选择可以这么做。
|
1 |
{ "node": 1, "time": 1 } |
用“node”作为片键,而“time”这个变化的字段作为一个复合片键来做。
第二种:单调递增的升序片键
升序片键或导致的问题就是数据写操作不能够均匀分布,一些片键会使应用程序能够达到集群能够提供的最大的写性能,有一些则不能,比如使用默认的_id做片键的情况。如果我们使用一个单调递增的“_id”或时间戳作为片键,在插入文档时,MongoDB会生成一个全局唯一的ObjectId标识符_id。不过,需要注意的一点是,这个标识符的前几位代表时间戳,这意味着_id是以常规的并且可预测的方式增长,即使_id有大的基数,在使用_id或者任意其他单调递增的数据作为片键时,所有的写入操作都会集中到最后一个分片中。导致性能不能够很好地均摊,这样也违背了分片的最初目的。不过,如果你的写入频率很低或者大多都是update()操作,单调递增的片键不会对性能有很大影响,一般来说,选择的片键要同时具有较大的基数与将请求分布在整个集群中,两个特性。
比方说我们有一个类似微博的服务,其中每个文档都包含一个条短消息、发送人以及发送时间。我们按发送时间字段来分片,取值为自公元元年起经过的秒数。
实例:微博
|
1 2 3 4 5 |
{ auth: "jerry", time: "1455755673", message: "Hello world!" } |
和往常一样,集合开始于某一个分片的初始块上,所有的插入和读取都落在这一个块上。一旦它变得足够大时,然后开始分裂。比如说(?,1455755673)和(1455755673,?)。由于是从片键中点把块分开来的,所以在我们分割块的那一刻,时间戳很可能已经远大于1455755673了。这意味着再往后所有的插入都会落到第二个块上,不会再有插入操作命中第一个块。一旦第二个块填满了,它就会分裂成(1455755673,1455759834)和(1455759834,?)两个块。但是因为从现在起时间都在1455759834之后,所以新的插入都会被添加到区间为(1455759834,?)的块上。而这个模式会持续下去:所有数据总是被添加到“最后”一个数据块上,即所有数据都会被添加到一个分片上。这种片键创造了一个单一且不可分散的热点。
同样更好的选择就是使用:
|
1 |
{ "auth": 1, "time": 1 } |
用“auth”作为片键,而“time”这个变化的字段作为一个符合的复合片键来做。
第三种:随机片键
有时为了避免热点,会采用一个取值随机的字段来做分片,采用这种片键一开始还不错,但是随着数据量越来越大,他会越来越慢。比如我们在分片集合中存储照片缩略图,每个文档包含了照片的二进制数据,二进制数据的MD5散列值,以及描述等字段,我们决定在MD5散列值上做分片。
随着集合的增长,我们最终会得到一组均匀分布于各分片的数据块。目前一切正常。现在假设我们非常忙而Shard2上的一个块填满并分裂了,配置服务器注意到Shard2比Shard1多出了10个块并判定应该抹平分片间的差距,这样MongoDB就需要随机加载5个块的数据到内存中并发给Shard1,考虑到数据序列的随机性,一般情况下这些数据可能不会出现在内存中,所以此时的MongoDB会给RAM带来更大的压力,而且还会引发大量的磁盘IO。另外,片键上必须有索引,因此如果选择了从不依据索引查询的随机键,基本上可以说浪费了一个索引,另一方面索引的增加会降低写操作的速度,所以降低索引量也是非常必要的。
说了这么多到底该使用哪一种偏见,这个真的没有一个准确的答案,需要根据自己的应用程序以及需求来定义片键。但在选定一个片键时,不防先想一想下面这些问题的答案?
1.写操作是怎么样的,有多大?
2.系统没小时会写多少数据,每天呢,高峰期呢?
3.那些字段是随机的,那些是增长的?
4.读操作是怎么样的,用户在访问那些数据?
5.数据索引做了吗?应不应该索引呢?
6.数据总量有多少?
总的来说,在进行分片前,你需要清楚的了解你的数据。