一、MySQL高可用系统
MySQL高可用,顾名思义就是当MySQL主机或服务发生任何故障时能够立马有其他主机顶替其工作,并且最低要求是要保证数据一致性。因此,对于一个MySQL高可用系统需要达到的目标有以下几点:
- 数据一致性保证这个是最基本的同时也是前提,如果主备的数据的不一致,那么切换就无法进行,当然这里的一致性也是一个相对的,但是要做到最终一致性。
- 故障快速切换,当master故障时这里可以是机器故障或者是实例故障,要确保业务能在最短时间切换到备用节点,使得业务受影响时间最短。
- 简化日常维护,通过高可用平台来自动完成高可用的部署、维护、监控等任务,能够最大程度的解放DBA手动操作,提高日常运维效率。
- 统一管理,当复制集很多的情况下,能够统一管理高可用实例信息、实例信息、监控信息、切换信息等。
- 高可用的部署要对现有的数据库架构无影响,如果因为部署高可用,需要更改或者调整数据库架构则会导致成本增加。
目前MySQL高可用方案可以一定程度上实现数据库的高可用,比如MMM,heartbeat+drbd,NDB Cluster等。还有MariaDB的Galera Cluster,以及MySQL 5.7.17 Group Replication等。这些高可用软件各有优劣。在进行高可用方案选择时,主要是看业务还有对数据一致性方面的要求。最后出于对数据库的高可用和数据一致性的要求,目前推荐使用MHA架构,因为MySQL GP还不能在生产使用,但是我相信以后慢慢就会被用到生产环境的。
二、MHA技术介绍
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。除了failover之外,MHA还支持在线master切换,非常安全和高效,大概只需要(0.5 ~ 2秒)的阻塞写时间。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。当然,如果你处于成本考虑,也可以使用两个节点的MHA,一主一从(实测过的)。
总结一下,MHA提供了如下功能:
- master自动监控,故障转移一体化(Automated master monitoring and failover)
MHA可以在一个复制组中监控master的状态,如果挂了,就可以自动的做failover。
MHA通过所有slave的差异relay-log来保证数据的一致性。
MHA在做故障转移,日志补偿这些动作的时候,通常只需要10~30秒。
通常情况下,MHA会选择最新的slave作为new master,但是你也可以指定哪些是候选maser,那么新master选举的时候,就从这些host里面挑。
导致复制环境中断的一致性问题,在MHA中是不会发生的,请放心使用。
在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5及以上版本的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
- 手工-交互式master故障转移(Interactive manually initiated Master Failover)
MHA可以配置成手工-交互式方式进行故障转移,不支持监控master的状态。
- 非交互式master故障转移 (Non-interactive master failover)
非交互式,自动的故障转移,不提供监控master状态功能,监控可以交给其他组件做(如:Pacemaker heartbeat)。
- 在线master切换 (Online switching master to a different host)
如果你有更快,更好的master,计划要将老master替换成新的master,那么这个功能特别适合这样的场景。
这不是master真的挂掉了,只是我们有很多需求要进行master例行维护。
MHA的优点
1. master failover和slave promotion非常快速。
2. 自动探测,多重检测,切换过程中支持调用其他脚本的接口。
3. master crash不会导致数据不一致,自动补齐数据,维护数据一致性。
4. 不需要修改复制的任何设置,简单易部署,对现有架构无影响。
5. 不需要增加很多额外的机器来部署MHA,支持多实例集中管理。
6. 没有任何性能影响。
7. 支持在线切换。
8. 跨存储引擎,支持任何引擎。
官方介绍:https://code.google.com/p/mysql-master-ha
三、MHA工作流程
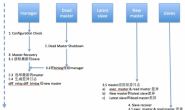
下图展示了如何通过MHA Manager管理多组主从复制,可以将MHA工作原理总结为如下:

1)MHA如何监控master和故障转移?
下面的流程,就是masterha_manager做的事情
1.1 验证复制设置以及确认当前master状态
- 连接所有hosts,MHA自动来确认当前master是哪个,配置文件中无需指定哪个是master。
- 如果其中有任何一个slave挂了,脚本立即退出,停止监控。
- 如果有一些必要的脚本没有在MHA Node节点安装,那么MHA在这个阶段终止,且停止监控。
1.2 监控master
- 监控master,直到master挂了。
这个阶段,MHA不会监控slave,Stopping/Restarting/Adding/Removing操作在slave上,不会影响当前的MHA监控进程。当你添加或者删除slave的时候,请更新好配置文件,最好重启MHA。
1.3 检测master是否失败
- 如果MHA Manger三次间隔时间都没办法连接master server,就会进入这个阶段。
- 如果你设置了secondary_check_script ,那么MHA会调用脚本做二次检测来判断master是否是真的挂了。
接下来的步骤,就是masterha_master_switch的工作流程了。
1.4 再次验证slave的配置
- 如果发现任何不合法的复制配置(有些slave的master不是同一个),那么MHA会停止监控,且报错。可以设置ignore_fail忽略。
这一步是处于安全考虑,很有可能,复制的配置文件已经被改掉了,所以double check是比较推荐的做法。
- 检查最后一次failover(故障转移)的状态
如果上一次的failover报错,或者上一次的failover结束的太近(默认3天),MHA停止监控,停止failover,那么在masterha_manager命令中设置ignore_last_failover,wait_on_failover_error来改变这一检测。这么做,也是出于安全考虑。频繁的failover,检查下是否网络出问题,或者其他错误呢?
1.5 关掉失败的master的服务器(可选)
- 如果在配置文件中定义了master_ip_failover_script and/or shutdown_script ,MHA会调用这些的脚本。
- 关闭dead master,避免脑裂(值得商榷)。
1.6 恢复一台新master
- 从crashed master服务器上保存binlog到Manager(如果可以的话
如果dead master可以SSH的话,拷贝binary logs从最新的slave上的end_log_pos(Read_Master_Log_Pos)位置开始拷贝。
- 选举新master
一般根据配置文件的设置来决定选举谁,如果想设置一些候选master,设置candidate_master=1;如果想设置一些host,永远都不会选举,设置no_master=1;确认最新的slave (这台slave拥有最新的relay-log)。
- 恢复和提升新master
根据老master binlog生成差异日志,应用日志到new master,如果这一步发生错误(如:duplicate key error),MHA停止恢复,并且其余的slave也停止恢复。
2)MHA如何在线快速切换master?
下面的步骤,就是masterha_master_switch --master_state=alive做的事情。
2.1 验证复制设置以及确认当前master状态
- 连接配置文件中列出的所有hosts,MHA自动来确认当前master是哪个,配置文件中无需指定哪个是master。
- 执行 flush tables 命令在master上(可选). 这样可以缩短FLUSH TABLES WITH READ LOCK的时间。
- 既不监控master,也不会failover。
- 检查下面的条件是否满足。
A. IO线程是否在所有slave上都是running。
B. SQL线程是否在所有slave上都是running。
C. Seconds_Behind_Master 是否低于1秒(--running_updates_limit=N)。
D. master上是否没有长的更新语句大于1秒。
2.2 确认新master
- 新master需要设置:
--new_master_host参数。 - 原来的master和新的master必须要有同样的复制过滤条件(binlog-do-db and binlog-ignore-db)。
2.3 当前master停写
- 如果你在配置中定义了master_ip_online_change_script,MHA会调用它。可以通过设置SET GLOBAL read_only=1来完美的阻止写入。
- 在老master上执行FLUSH TABLES WITH READ LOCK来阻止所有的写(
--skip_lock_all_tables可以忽略这一步)。
2.4 等待其他slave追上当前master,同步无延迟
- 调用这个函数MASTER_LOG_POS()。
2.5 确保新master可写
- 执行SHOW MASTER STATUS来确定新master的binary log文件名和position。
- 如果设置了master_ip_online_change_script,会调用它。可以创建写权限的用户,SET GLOBAL read_only=0。
2.6 让其他slave指向新master
- 并行执行CHANGE MASTER, START SLAVE。
四、MHA组件介绍
MHA软件由两部分组成,Manager工具包和Node工具包,具体的说明如下。
Manager工具包主要包括以下几个工具:
|
1 2 3 4 5 6 7 8 9 |
masterha_check_ssh #检查MHA的SSH配置状况; masterha_check_repl #检查MySQL复制状况; masterha_check_status #检测当前MHA运行状态; masterha_master_monitor #检测master是否宕机; masterha_master_switch #控制故障转移(自动或者手动); masterha_conf_host #添加或删除配置的server信息; masterha_secondary_check #故障切换时二次检测脚本; masterha_manager #启动MHA; masterha_stop #关闭MHA; |
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
|
1 2 3 4 |
save_binary_logs #保存和复制master的二进制日志; apply_diff_relay_logs #识别差异的中继日志事件并将其差异的事件应用于其他的slave; filter_mysqlbinlog #去除不必要的ROLLBACK事件(MHA已不再使用这个工具); purge_relay_logs #清除中继日志(不会阻塞SQL线程); |
注意:为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL半同步复制。关于半同步复制原理各位自己进行查阅(不是必须)。
<参考>