在MySQL主备环境下,主备同步过程如下,主库更新产生binlog,备库io线程拉取主库binlog生成relay log。备库sql线程执行relay log从而保持和主库同步。

理论上主库有更新时,备库都存在延迟,且延迟时间为备库执行时间+网络传输时间,即t4-t2。但实际情况是,我们一般都是通过Slave上执行SHOW SLAVE STATUS命令得到Seconds_Behind_Master列,理论上的显示了Slave的延时,但由于各种各样的情况,这个值并不总是准确的:
- 从库Seconds_Behind_Master是通过拿Slave服务器当前的时间戳与SQL线程读取relay log中的事件的时间戳相比得到的,所以只有当SQL线程执行事件时才会报告延迟,不然Seconds_Behind_Master=0。
- 如果备库复制线程没有运行,则Seconds_Behind_Master = NULL。
- 即使备库线程正在运行,备库有时候可能无法计算延时,如果发生这种情况,Seconds_Behind_Master会报0或者NULL。
- 如果网络延迟,导致从库拉取日志速度跟不上主库;但此时从库IO线程跟SQL线程在同一位点,那么Seconds_Behind_Master值为0,误以为没有延迟。
- 一个大事务可能会导致延迟波动,例如一个事务更新数据长达1个小时,最后提交;这条更新语句将比它实际发生时间要晚一个小时才记录到二进制日志中(Binlog记录开始执行时间以及执行时间),当备库执行这条语句时,会临时报告备库延迟1小时,然后又很快变为0。
- 长期未提交的事物延迟(如begin…dml…wait…commit),会造成延迟的瞬时增加。
- 表中没有主键也会造成主从延迟,由于表中没有主键,所以导致了每一个事务条目的更新都是全表扫描,如果表中很很多的数据,则备库执行该更新的事务条目的时候,就会出现很多的全表扫描更新;进一步说明就是,由于表中没有主键,在ROW模式下,每删一条数据都会做全表扫,也就是说一条delete,如果删了10条,会做10次全表扫,所以slave会一直卡住。
首先,我们先看下SLAVE的状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
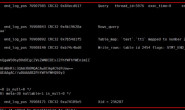
mysql> show slave status\G *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event *** Master_Log_File: mysql-bin.000327 Read_Master_Log_Pos: 668711237 Relay_Log_File: mysql-relay-bin.002999 Relay_Log_Pos: 214736858 Relay_Master_Log_File: mysql-bin.000327 Slave_IO_Running: Yes Slave_SQL_Running: Yes *** Skip_Counter: 0 Exec_Master_Log_Pos: 654409041 Relay_Log_Space: 229039311 *** Seconds_Behind_Master: 3296 *** |
可以看到Seconds_Behind_Master的值是3296,也就是SLAVE至少延迟了3296秒。
我们再来看下SLAVE上的2个REPLICATION进程状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> show full processlist\G *************************** 1. row *************************** Id: 6 User: system user Host: db: NULL Command: Connect Time: 22005006 State: Waiting for master to send event Info: NULL *************************** 2. row *************************** Id: 7 User: system user Host: db: NULL Command: Connect Time: 3293 State: Updating Info: UPDATE ** SET ** WHERE ** |
可以看到SQL线程一直在执行UPDATE操作,注意到Time的值是3293,看起来像是这个UPDATE操作执行了3293秒,一个普通的SQL而已,肯定不至于需要这么久。
实际上,在REPLICATION进程中,Time这列的值可能有几种情况:
1、SQL线程当前执行的binlog(实际上是relay log)中的timestamp和IO线程最新的timestamp的差值,这就是通常大家认为的Seconds_Behind_Master值。
2、SQL线程当前如果没有活跃SQL在执行的话,Time值就是SQL线程的idle time;
而IO线程的Time值则是该线程自从启动以来的总时长(多少秒),如果系统时间在IO线程启动后发生修改的话,可能会导致该Time值异常,比如变成负数,或者非常大。
来看下面几个状态:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#设置pager,只查看关注的几个status值 mysql> pager cat | egrep -i 'system user|Exec_Master_Log_Pos|Seconds_Behind_Master|Read_Master_Log_Pos' #这是没有活跃SQL的情况,Time值是idle time,并且Seconds_Behind_Master为0 mysql> show processlist; show slave status\G | 6 | system user | | NULL | Connect | 22004245 | Waiting for master to send event | NULL | | 7 | system user | | NULL | Connect | 13 | Has read all relay log;** Read_Master_Log_Pos: 445167889 Exec_Master_Log_Pos: 445167889 Seconds_Behind_Master: 0 #和上面一样 mysql> show processlist; show slave status\G | 6 | system user | | NULL | Connect | 22004248 | Waiting for master to send event | NULL | | 7 | system user | | NULL | Connect | 16 | Has read all relay log;** Read_Master_Log_Pos: 445167889 Exec_Master_Log_Pos: 445167889 Seconds_Behind_Master: 0 #这时有活跃SQL了,Time值是和Seconds_Behind_Master一样,即SQL线程比IO线程慢了1秒 mysql> show processlist; show slave status\G | 6 | system user | | NULL | Connect | 22004252 | Waiting for master to send event | NULL | | 7 | system user | | floweradmin | Connect | 1 | Updating | update ** Read_Master_Log_Pos: 445182239 Exec_Master_Log_Pos: 445175263 Seconds_Behind_Master: 1 #和上面一样 mysql> show processlist; show slave status\G | 6 | system user | | NULL | Connect | 22004254 | Waiting for master to send event | NULL | | 7 | system user | | floweradmin | Connect | 1 | Updating | update ** Read_Master_Log_Pos: 445207174 Exec_Master_Log_Pos: 445196837 Seconds_Behind_Master: 1 |
好了,最后我们说下如何正确判断SLAVE的延迟情况:
1、首先看Relay_Master_Log_File和Master_Log_File是否有差异;
2、如果Relay_Master_Log_File和Master_Log_File是一样的话,再来看Exec_Master_Log_Pos和Read_Master_Log_Pos的差异,对比SQL线程比IO线程慢了多少个binlog事件;
3、如果Relay_Master_Log_File和Master_Log_File不一样,那说明延迟可能较大,需要从MASTER上取得binlog status,判断当前的binlog和MASTER上的差距;
因此,相对更加严谨的做法是:
在第三方监控节点上,对MASTER和SLAVE同时发起SHOW BINARY LOGS和SHOW SLAVE STATUS\G的请求,最后判断二者binlog的差异,以及Exec_Master_Log_Pos和Read_Master_Log_Pos的差异。
例如:
在MASTER上执行SHOW BINARY LOGS 的结果是:
|
1 2 3 4 5 6 |
+------------------+--------------+ | Log_name | File_size | +------------------+--------------+ | mysql-bin.000009 | 1073742063 | | mysql-bin.000010 | 107374193 | +------------------+--------------+ |
而在SLAVE上执行SHOW SLAVE STATUS\G 的结果是:
|
1 2 3 4 5 6 7 8 9 10 11 |
Master_Log_File: mysql-bin.000009 Read_Master_Log_Pos: 668711237 Relay_Master_Log_File: mysql-bin.000009 Slave_IO_Running: Yes Slave_SQL_Running: Yes *** Exec_Master_Log_Pos: 654409041 *** Seconds_Behind_Master: 3296 *** |
这时候,SLAVE实际的延迟应该是:
mysql-bin.000009 这个binlog中的binlog position 1073742063 和 SLAVE上读取到的binlog position之间的差异延迟,即:
|
1 |
1073742063 - 654409041 = 419333022个binlog event |
并且还要加上 mysql-bin.000010这个binlog已经产生的107374193个binlog event,共
|
1 |
107374193 + 419333022 = 526707215个binlog event |
后记更新:
1、可以在MASTER上维护一个监控表,它只有一个字段,存储这最新最新时间戳(高版本可以采用event_scheduler来更新,低版本可以用cron结合自动循环脚本来更新),在SLAVE上读取该字段的时间,只要MASTER和SLAVE的系统时间一致,即可快速知道SLAVE和MASTER延迟差了多少。不过,在高并发的系统下,这个时间戳可以细化到毫秒,否则哪怕时间一致,也是有可能会延迟数千个binlog event的。
2、网友(李大玉,QQ:407361231)细心支出上面的计算延迟有误,应该是mysql-bin.000009的最大事件数减去已经被执行完的事件数,即1073742063 – 654409041= 419333022个binlog event,再加上mysql-bin.000010这个binlog已经产生的107374193个binlog event,共526707215个binlog event。