一、MySQL InnoDB死锁阐述
在MySQL中,当两个或以上的事务相互持有和请求锁,并形成一个循环的依赖关系,就会产生死锁。多个事务同时锁定同一个资源时,也会产生死锁。在一个事务系统中,死锁是确切存在并且是不能完全避免的。 InnoDB会自动检测事务死锁,立即回滚其中某个事务,并且返回一个错误。它根据某种机制来选择那个最简单(代价最小)的事务来进行回滚。偶然发生的死锁不必担心,但死锁频繁出现的时候就要引起注意了。InnoDB存储引擎有一个后台的锁监控线程,该线程负责查看可能的死锁问题,并自动告知用户。
在MySQL 5.6之前,只有最新的死锁信息可以使用show engine innodb status命令来进行查看。使用Percona Toolkit工具包中的pt-deadlock-logger可以从show engine innodb status的结果中得到指定的时间范围内的死锁信息,同时写入文件或者表中,等待后面的诊断分析。对于pt-deadlock-logger工具的更多信息可以参考手册。 如果使用的是MySQL 5.6或以上版本,您可以启用一个新增的参数innodb_print_all_deadlocks把InnoDB中发生的所有死锁信息都记录在错误日志里面。
产生死锁的必要条件
1. 多个并发事务(2个或者以上);
2. 每个事务都持有锁(或者是已经在等待锁);
3. 每个事务都需要再继续持有锁(为了完成事务逻辑,还必须更新更多的行);
4. 事务之间产生加锁的循环等待,形成死锁。
总结:当两个或多个事务相互持有对方需要的锁时,就会产生死锁,如下图:
")
死锁实例
创建环境
|
1 2 3 |
create table money(id int primary key,price int); insert into money values(1,1000); insert into money values(2,1000); |
事务A: 更新表,id=1的记录
|
1 2 3 4 5 6 |
mysql> start transaction; Query OK, 0 rows affected (0.01 sec) mysql> update money set price=2000 where id=1; Query OK, 1 row affected (0.03 sec) Rows matched: 1 Changed: 1 Warnings: 0 |
事务B: 更新表,id=2的记录
|
1 2 3 4 5 6 |
mysql> start transaction; Query OK, 0 rows affected (0.01 sec) mysql> update money set price=2000 where id=2; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 |
事务A: 更新表,id=2的记录,此时会卡住(因为这条记录被加上了X锁)
|
1 |
mysql> update money set price=3000 where id=2; |
事务B: 更新表,id=1的记录,此时会报错事务进行回滚,并且事务1会执行更新id=2的记录
|
1 2 |
mysql> update money set price=3000 where id=1; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
上述,事务抛出1213这个出错提示,即发生了死锁,上例中当两个事务都执行了第一条UPDATE语句,更新了一行数据,同时也锁定了该行数据,接着每个事务都尝试去执行第二条UPDATE语句,却发现该行已经被对方锁定,然后两个事务都等待对方释放锁,同时又持有对方需要的锁,则陷入死循环。除非有外部因素接入才可能解除死锁。为了解决这种问题,数据库系统实现了各种死锁检测和死锁超时机制。
二、MySQL InnoDB死锁检测
尽量不出现死锁
在代码层调整SQL操作顺序,或者缩短事务长度,以避免出现死锁。
碰撞检测
当死锁出现时,Innodb会主动探知到死锁,并回滚了某一苦苦等待的事务。问题来了,Innodb是怎么探知死锁的?
核心就是数据库会把事务单元锁维持的锁和它所等待的锁都记录下来,Innodb提供了wait-for graph算法来主动进行死锁检测,每当加锁请求无法立即满足需要进入等待时,wait-for graph算法都会被触发。当数据库检测到两个事务不同方向地给同一个资源加锁(产生循序),它就认为发生了死锁,触发wait-for graph算法。比如,事务1给A加锁,事务2给B加锁,同时事务1给B加锁(等待),事务2给A加锁就发生了死锁。那么死锁解决办法就是终止一边事务的执行即可,这种效率一般来说是最高的,也是主流数据库采用的办法。
Innodb目前处理死锁的方法就是将持有最少行级排他锁的事务进行回滚。这也是相对比较简单的死锁回滚方式。死锁发生以后,只有部分或者完全回滚其中一个事务,才能打破死锁。对于事务型的系统,这是无法避免的,所以应用程序在设计必须考虑如何处理死锁。大多数情况下只需要重新执行因死锁回滚的事务即可。
wait-for graph原理
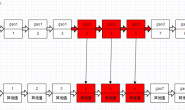
我们怎么知道图中四辆车是死锁的?
")
他们相互等待对方的资源,而且形成环路!我们将每辆车看为一个节点,当节点1需要等待节点2的资源时,就生成一条有向边指向节点2,最后形成一个有向图。我们只要检测这个有向图是否出现环路即可,出现环路就是死锁!这就是wait-for graph算法。
")
Innodb将各个事务看为一个个节点,资源就是各个事务占用的锁,当事务1需要等待事务2的锁时,就生成一条有向边从1指向2,最后行成一个有向图。
等锁超时
死锁超时也是一种常见的做法,就是等待锁持有时间,如果说一个事务持有锁超过设置时间的话,就直接抛出一个错误,参数innodb_lock_wait_timeout用来设置超时时间。如果有些用户使用哪种超长的事务,你就需要把锁超时时间大于事务执行时间。在这种情况下这种死锁超时的方式就会导致每一个死锁超时被发现的时间是无法接受的。
不要太担心死锁,你可能会在MySQL error log中看到关于死锁的警告信息,或者在show engine InnoDB status输出中看到它。尽管看起来是一个可怕的名字,但deadlock不是一个严重的问题,对于InnoDB来说,通常不需要做任何纠正操作。当两个事务开始修改多个表时,如果访问表的顺序不同,会出现互相等待对方释放锁,然后才能继续处理的情况。MySQL会立刻发现这种情况并且终止较小的事务,允许其他的事务执行。
你的应用程序的确需要错误处理逻辑来重启该事务。当你重新执行相同的SQL语句时,原来的时间问题不再适用:要么其他的事务已经执行完成,这样你就可以执行事务了,要么其他的事务还在处理过程中,你的事务只能等它结束。
如果不断警告发生死锁,你可能要review你的应用程序源代码,调整SQL操作顺序,或者缩短事务长度。你可以启用innodb_print_all_deadlocks选项,把deadlock信息记录到MySQL的错误日志总,而不是仅仅通过show engine innob status查看。
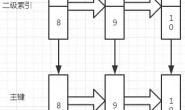
锁跟索引的关系
这时我们要注意到,money表虽然没有添加索引,但是InnoDB存储引擎会使用隐式的主键来进行锁定。对于没有索引或主键的表来说,那么MySQL会给整张表的所有数据行的加行锁。这里听起来有点不可思议,但是当sql运行的过程中,MySQL并不知道哪些数据行是id=1(没有索引嘛),如果一个条件无法通过索引快速过滤,存储引擎层面就会将所有记录加锁后返回,再由MySQL Server层进行过滤。但在实际使用过程当中,MySQL做了一些改进,在MySQL Server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录释放锁 (违背了二段锁协议的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。可见即使是MySQL,为了效率也是会违反规范的。所以对一个数据量很大的表做批量修改的时候,如果无法使用相应的索引,MySQL过滤数据的时候特别慢,就会出现虽然没有修改某些行的数据,但是它们还是被锁住了的现象。
三、死锁扩展—读写锁与U锁
再谈读写锁与U锁,在数据库中还有一种U锁,U锁非常简单是用来解决读写锁死锁问题。当然在现代数据库中读写锁的死锁问题不会出现,因为使用了U锁机制。如下图:
")
事务1与事务2第一条语句都是查询A,然后事务1对A进行更新操作,但是由于事务2的读锁对A还没有释放,所以事务1要等待;如果此时事务2也要对A进行更新操作,由于事务1对A的读锁还没有释放,所以事务2要等待。此时发生了什么?就是死锁。
那么上述情况对应到事务中哪种情况就会出现死锁呢?看一下下面这条语句。
|
1 |
UPDATE table_name SET A=A-1 WHERE id=100; |
这条语句中会先进行id=100的查询,申请一个读锁;然后执行SET A=A-1操作,申请一个写锁。也就是对一条记录进行读写锁。如果有两个人同时执行这条语句,第一个人执行id=100的查询,第二个人也执行id=100的查询,第一个人执行SET A=A-1操作,第二个人执行SET A=A-1操作,那么就产生死锁。那么可以看到如果你使用读写锁的话,碰到这种场景就会死锁,那么基本没法用了。
那么为什么我们数据库里面不会出现这种情况呢?其实原因就是我们使用了U锁,U锁很简单就是会提前判断你这个事务中有没有针对一个事务的写操作,如果检查到有写锁,那么它会提前在你申请锁的时候把原来的读锁变成写锁。当锁变成写锁之后其他的读写操作都无进来这个事务内了,也就避免了死锁。
MySQL目前不支持U锁,SQLserver是支持U锁的。
四、开启死锁输出日志
在 MySQL 中可以把死锁信息打印到错误日志里,开启如下变量即可。
|
1 |
mysql> set global innodb_print_all_deadlocks = 1; |
然后可以再去测试一下死锁,看看错误日志中会出现如下一条信息:
2016-12-16 20:16:30 7f126a1e4700InnoDB: transactions deadlock detected, dumping detailed information.
当然除了这么一条死锁信息,还有更为详细的SQL语句和死锁信息和事务信息。
五、经常出现的死锁案例
死锁:当两个事务都尝试获取其他事务已经持有的锁时,就会出现死锁。
")
创建实验环境:
|
1 2 3 4 |
CREATE TABLE t1 (id int unsigned NOT NULL PRIMARY KEY, val varchar(10)) ENGINE=InnoDB; CREATE TABLE t2 LIKE t1; INSERT INTO db1.t1 VALUES (1, 'aa'), (2, 'ab'), (3, 'ac'), (4, 'ad'), (5, 'ae'), (6, 'af'); INSERT INTO db1.t2 VALUES (1, 'ba'), (2, 'bb'), (3, 'bc'), (4, 'bd'), (5, 'be'), (6, 'bf'); |
Example 1: Two Transactions Updating Two Records In Two Tables
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
transaction 1> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 1> UPDATE db1.t1 SET val = 'aa1' WHERE id = 1; Query OK, 1 row affected (0.03 sec) Rows matched: 1 Changed: 1 Warnings: 0 transaction 2> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 2> UPDATE db1.t2 SET val = 'ba2' WHERE id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 -- Next statement will block waiting for the lock held by Connection 2: transaction 1> UPDATE db1.t2 SET val = 'ab1' WHERE id = 1; transaction 2> UPDATE db1.t1 SET val = 'aa2' WHERE id = 1; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
Example 2: Two Transactions Updating Two Records In One Table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
transaction 1> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 1> UPDATE db1.t1 SET val = 'aa1' WHERE id = 1; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 transaction 2> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 2> UPDATE db1.t1 SET val = 'ab2' WHERE id = 2; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 -- Next statement will block waiting for the lock held by Connection 2: transaction 1> UPDATE db1.t1 SET val = 'ab1' WHERE id = 2; transaction 2> UPDATE db1.t1 SET val = 'aa2' WHERE id = 1; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
Example 3: Two Transactions Deleting a Series of Records In One Table
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
transaction 1> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 1> DELETE FROM db1.t1 WHERE id = 1; Query OK, 1 row affected (0.00 sec) transaction 2> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 2> DELETE FROM db1.t1 WHERE id = 6; Query OK, 1 row affected (0.00 sec) transaction 1> DELETE FROM db1.t1 WHERE id = 2; Query OK, 1 row affected (0.00 sec) transaction 2> DELETE FROM db1.t1 WHERE id = 5; Query OK, 1 row affected (0.01 sec) transaction 1> DELETE FROM db1.t1 WHERE id = 3; Query OK, 1 row affected (0.00 sec) transaction 2> DELETE FROM db1.t1 WHERE id = 4; Query OK, 1 row affected (0.00 sec) -- Next statement will block waiting for the lock held by Connection 2: transaction 1> DELETE FROM db1.t1 WHERE id = 4; transaction 2> DELETE FROM db1.t1 WHERE id = 3; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
Example 4: Deleting Non-Existing Rows(REPEATABLE READ isolation)
|
1 2 3 4 5 6 7 8 9 |
mysql> SET GLOBAL TRANSACTION ISOLATION LEVEL REPEATABLE READ; Query OK, 0 rows affected (0.00 sec) mysql> CREATE TABLE db1.t3 (id int unsigned NOT NULL PRIMARY KEY) ENGINE=InnoDB; Query OK, 0 rows affected (0.11 sec) mysql> INSERT INTO db1.t3 VALUES (1),(5); Query OK, 2 rows affected (0.02 sec) Records: 2 Duplicates: 0 Warnings: 0 |
两个并发事务试图删除带有主键的非现有的行,然后试图插入行,可能会导致死锁在可重复读的事务隔离级别︰
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
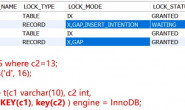
transaction 1> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 1> DELETE FROM t1 WHERE id = 2; Query OK, 0 rows affected (0.00 sec) transaction 2> START TRANSACTION; Query OK, 0 rows affected (0.00 sec) transaction 2> DELETE FROM t1 WHERE id = 4; Query OK, 0 rows affected (0.01 sec) -- Next statement will block waiting for the insert intention lock held by Connection 2: transaction 1> INSERT INTO t1 VALUES (2); -- At this stage information_schema.INNODB_LOCKS shows for the two transactions: mysql> SELECT * FROM information_schema.INNODB_LOCKS\G *************************** 1. row *************************** lock_id: 25205128:0:163881:3 lock_trx_id: 25205128 lock_mode: X,GAP lock_type: RECORD lock_table: `db1`.`t3` lock_index: `PRIMARY` lock_space: 0 lock_page: 163881 lock_rec: 3 lock_data: 5 *************************** 2. row *************************** lock_id: 25205129:0:163881:3 lock_trx_id: 25205129 lock_mode: X,GAP lock_type: RECORD lock_table: `db1`.`t3` lock_index: `PRIMARY` lock_space: 0 lock_page: 163881 lock_rec: 3 lock_data: 5 2 rows in set (0.00 sec) transaction 2> INSERT INTO t1 VALUES (4); ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction |
INNODB_LOCKS输出具有lock_data = 5,显示每个事务持有的gap lock。
在InnoDB中死锁信息如下︰
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
InnoDB: transactions deadlock detected, dumping detailed information. 1 161219 16:20:14 2 *** (1) TRANSACTION: 3 TRANSACTION 25205152, ACTIVE 34 sec inserting 4 mysql tables in use 1, locked 1 5 LOCK WAIT 3 lock struct(s), heap size 376, 2 row lock(s) 6 MySQL thread id 11034, OS thread handle 0x7f57d02a6700, query id 467882 localhost 127.0.0.1 root update 7 INSERT INTO db1.t3 VALUES (2) 8 *** (1) WAITING FOR THIS LOCK TO BE GRANTED: 9 RECORD LOCKS space id 0 page no 163881 n bits 72 index `PRIMARY` of table `db1`.`t3` trx id 25205152 lock_mode X locks gap before rec insert intention waiting 10 Record lock, heap no 3 PHYSICAL RECORD: n_fields 3; compact format; info bits 0 0: len 4; hex 00000005; asc ;; 1: len 6; hex 00000180994c; asc L;; 2: len 7; hex e500001089011d; asc ;; 11 *** (2) TRANSACTION: 12 TRANSACTION 25205268, ACTIVE 28 sec inserting 13 mysql tables in use 1, locked 1 14 3 lock struct(s), heap size 376, 2 row lock(s) 15 MySQL thread id 11035, OS thread handle 0x7f57d02e7700, query id 467928 localhost 127.0.0.1 root update 16 INSERT INTO db1.t3 VALUES (4) 17 *** (2) HOLDS THE LOCK(S): 18 RECORD LOCKS space id 0 page no 163881 n bits 72 index `PRIMARY` of table `db1`.`t3` trx id 25205268 lock_mode X locks gap before rec 19 Record lock, heap no 3 PHYSICAL RECORD: n_fields 3; compact format; info bits 0 0: len 4; hex 00000005; asc ;; 1: len 6; hex 00000180994c; asc L;; 2: len 7; hex e500001089011d; asc ;; 20 *** (2) WAITING FOR THIS LOCK TO BE GRANTED: 21 RECORD LOCKS space id 0 page no 163881 n bits 72 index `PRIMARY` of table `db1`.`t3` trx id 25205268 lock_mode X locks gap before rec insert intention waiting 23 Record lock, heap no 3 PHYSICAL RECORD: n_fields 3; compact format; info bits 0 0: len 4; hex 00000005; asc ;; 1: len 6; hex 00000180994c; asc L;; 2: len 7; hex e500001089011d; asc ;; 24 *** WE ROLL BACK TRANSACTION (2) |
第 1 行是死锁发生的时间。如果你的应用程序捕捉和记录死锁错误到日志中,那么你可以根据这个时间戳和应用程序日志中的死锁错误的时间戳进行匹配。这样你可以得到已回滚的事务,及事务中的所有语句。
第 3 和 12 行,注意事务的序号和活跃时间。如果你定期地把 show engine innodb status 的输出信息记录到日志文件(这是一个很好的做法),那么你就可以使用事务编号在之前的输出日志中查到同一个事务中所希望看到的更多的语句。活跃时间提供了一个线索来判断这个事务是单个语句的事务,还是包含多个语句的事务。
第 4 和 13行,使用到的表和锁只是针对于当前的语句。因此,使用到一张表,并不意味着事务仅仅涉及到一张表。
第 5 和 14 行,这里的信息需要重点关注,因为它告诉我们事务做了多少的改变,也就是 “undo log entries”;”row lock(s)” 则告诉我们持有多少行锁。这些信息都会提示我们这个事务的复杂程度。
第 6 和 15 行,留意线程 ID、连接主机和用户。如果你在不同的应用程序中使用不同的 MySQL 用户,这将是另外一个好的习惯,这样你就可以根据连接主机和用户来定位到事务来自于哪个应用程序。
第 9 行,对于第一个事务,它只是显示了处于锁等待状态,在这个例子中,语句 INSERT INTO db1.t3 VALUES (4) 在等待表 t3 的 gap 锁。
第 9 和 10 行:”space id” 是表空间ID,”page no” 指出了这个表空间里面记录锁所在的数据页,”n bits” 不是数据页偏移量,而是锁位图里面的 bits 数。在第 10 行记录的 “heap no” 是数据页偏移量。然后第 10 行下面的数据显示了记录数据的十六进制编码。字段 0 表示聚集索引(即主键),忽略最高位,值为 5。字段 1 表示最后修改这条记录的事务的ID号,上面实例中的十进制值是 25205268,即是 TRANSACTION (2)。字段 2 表示回滚指针。从字段 3 开始,表示的是余下的行数据。通过阅读这些信息,我们可以准确知道哪一行被锁了,哪些是当前值。
第 17 和 18 行,对于第二个事务,显示了它持有的锁,在本示例中,是事务1 (TRANSACTION (1)) 所请求并等待中的 gap 锁。
第 20 和 21 行,显示了事务2 (TRANSACTION (2)) 所等待的锁的信息。在本例中,是事务1对 t3 表所产生的 gap 锁。
第 24 行,表示最终的处理结果,数据库选择回滚了哪个事务,一般选择回滚数据较小的事务。
另外,在InnoDB中有几种少数情况会产生共享记录锁:
1) 使用了 SELECT … LOCK IN SHARE MODE 的语句
2) 外键引用记录
3) 源表上的共享锁,使用了 INSERT INTO… SELECT 的语句
这些信息结合着其他数据可以帮助开发人员定位到那个事务。
Example 5︰Two Transactions execute ‘select * from t1 WHERE id =…for update’ In One Table(REPEATABLE READ isolation)
两个会话参与,在RR隔离级别下。
|
1 2 |
create table t1 (a int primary key ,b int); insert into t1 values (1,2),(2,3),(3,4),(11,22); |
开启两个事务会话。
|
1 2 |
transaction 1> begin; transaction 1> select * from t1 where a = 5 for update; |
获取记录(11,22)上的GAP X锁。
|
1 2 |
transaction 2> begin; transaction 2> select * from t1 where a = 5 for update; |
同上,GAP锁之间不冲突。
|
1 2 |
# block,wait transaction 1; transaction 1> insert into t1 values (4,5); |
|
1 2 |
# block,wait transaction 2,deadlock; transaction 2> insert into t1 values (4,5); |
引起这个死锁的原因是非插入意向的GAP X锁和插入意向X锁之间是冲突的。
六、如何避免死锁?
在了解死锁之后,我们可以做一些事情来避免它。
- 对应用程序进行调整/修改。在某些情况下,你可以通过把大事务分解成多个小事务,使得锁能够更快被释放,从而极大程度地降低死锁发生的频率。在其他情况下,死锁的发生是因为两个事务采用不同的顺序操作了一个或多个表的相同的数据集。需要改成以相同顺序读写这些数据集,换言之,就是对这些数据集的访问采用串行化方式。这样在并发事务时,就让死锁变成了锁等待。
- 修改表的schema,例如删除外键约束来分离两张表,或者添加索引来减少扫描和锁定的行。
- 如果发生了间隙锁,你可以把会话或者事务的事务隔离级别更改为 RC 隔离级别来避免,可以避免掉很多因为gap锁造成的死锁,但此时需要把binlog_format设置成row或者mixed格式。
- 为表添加合理的索引,不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大。
<参考>
通过Performance_schema获取造成死锁的事务语句