一、事务隔离级别
一个支持事务的关系型数据库必须要必备ACID(Atomicity、Consistency、Isolation、Durability,即原子性、一致性、隔离性、持久性),今天我们就来说说其中 Isolation,也就是“隔离性”。当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
隔离性其实比想象的要复杂,简单来说,隔离性的作用就是保证在多个事务并行执行时,相互之间不会影响;比如一个事务的修改对其他事务是不可见的,好似多个事务是串行执行的。
在谈隔离级别之前,你首先要知道,你隔离性越高,效率就会越低。因此很多时候,我们都要在二者之间寻找一个平衡点。
在古老的 ANSI SQL-92 标准中,其定义了四个隔离级别,分别包括:读未提交(READ UNCOMMITTED,RU)、读已提交(READ COMMITTED,RC)、可重复读(REPEATABLE READ,RR)和串行化(SERIALIZABLE,SRZ)。
但是很少有数据库厂商遵循这些标准,比如 Oracle 数据库就不支持 READ UNCOMMITTED 和 REPEATABLE READ 隔离级别。而 MySQL 数据库支持 ANSI SQL-92 定义的这四大古老事务隔离级别,并一直沿用至今。
在当时,ANSI SQL-92 定义的事务隔离级别依次解决 Dirty Read(脏读),Repeatable Read(不可重复读)、Phantom(幻读)。
| ANSI SQL-92 隔离级别 | |||
| Dirty Read | Non-repeatable Read | Phantom Read | |
| Read Uncommitted | Possible | Possible | Possible |
| Read Committed | Not Possible | Possible | Possible |
| Repeatable Read | Not Possible | Not Possible | Possible |
| Serializable | Not Possible | Not Possible | Not Possible |
在当时的学术界,认为只要解决了这三个问题,那么事务就是具有真正的隔离性。最终推导出具有两阶段加锁的 Serializable 事务隔离级别可以保证完整的隔离性。
但是!后来 Hal Berenson、Jim Gray 他们在 1995 年发表了一篇新的论文《A critique of ANSI SQL Isolation levels》,用来批判 ANSI SQL 的事务隔离级别,称原始的 ANSI SQL-92 隔离级别的定义存在严重问题/缺陷,并对其做出了补充。可以说,这篇论文应该基本上把 Jim Gray 在自己书中 《Transaction Processing: Concepts and Techniques》,对于事务隔离级别的定义进行“彻头彻尾”的批判。
论文的大意是除了 ANSI SQL 定义的三种并发问题,还有其他并发问题,如 Lost Update(P4)、Read Skew(A5A)、Write Skew(A5B)、New Phantom(A3B)等。之前定义的事务隔离级别,除了 SRZ 隔离级别,都无法解决。
然后论文引出了新的事务隔离级别 SI ,相比之前除了 SRZ,SI 有着更好的隔离性。
每一种隔离级别都规定了一个事务中所做的修改对其他事务的所见程度。为了尽可能减少事务间的影响,事务隔离级别越高安全性越好但是并发就越差;事务隔离级别越低,事务请求的锁越少,或者保持锁的时间就越短,这也就是为什么绝大多数数据库系统默认的事务隔离级别是 READ COMMITTED。MySQL 是支持 REPEATABLE READ 隔离级别,在这个级别下可以解决“不可重复读”的问题,是真正满足 ACID 中隔离性的要求的,但锁粒度比 READ COMMITTED 隔离级别要重。在 READ COMMITTED 隔离级别下是无法满足隔离性要求的,所以 MySQL 默认是 REPEATABLE READ 隔离级别。
相比于 Phantom Read,Dirty Read 和 Non-repeatable Read 要好理解很多,但因为大部分网络资料对于 MySQL 的 Phantom Read 的解释是存在误区的(把混淆快照读和当前读出现的现象当作 Phantom Read),本文仅对 Phantom Read 做详细的解释。
Note
做以下实验时需要关闭二进制日志功能或者将二进制日志记录格式设置为 ROW,不然会有一些你不了解的错误。下面我们从低级别往高级别介绍,级别越低数据一致性越好但是性能越差,而级别越高性能越好但问题越多。希望能说明白每个级别真正的含义。
- SERIALIZABLE
在这个级别,它通过强制事务串行执行,避免了前面说的一系列问题。简单来说就是对同一行记录,“写”会加“写锁”,“读”会加“读锁”。当出现读写锁冲突的时候,后访问的事务必须等前一个事务执行完成,才能继续执行。所以可能导致大量的超时和锁争用的问题,实际应用中也很少在本地事务中使用SERIALIABLE隔离级别,主要应用在InnoDB存储引擎的分布式事务中。
实例
事务A:更新表,但不提交
|
1 2 3 4 |
mysql> set session transaction isolation level serializable; mysql> select @@TX_isolation \G *************************** 1. row *************************** @@TX_isolation: SERIALIZABLE |
|
1 2 |
mysql> start transaction; mysql> update money set price=2000 where id=1; |
事务B:无法读取数据
|
1 2 3 4 |
mysql> set session transaction isolation level serializable; mysql> select @@TX_isolation \G *************************** 1. row *************************** @@TX_isolation: SERIALIZABLE |
|
1 2 3 |
mysql> start transaction; mysql> select * from money \G ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction |
事务A:提交数据
|
1 |
mysql> commit; |
事务B:可以读取事务A更新后的数据
|
1 2 3 4 5 6 7 |
mysql> select * from money\G *************************** 1. row *************************** id: 1 price: 2000 *************************** 2. row *************************** id: 2 price: 1000 |
可以看出SERIALIZABLE事务隔离级别最严厉,在进行查询时就会对相关行加上共享锁,其他事务对加“共享锁”的行只能进行读操作,而不能进行写操作。一旦有事务对行加了“独占锁”,其他事务连读都不能操作。
- REPEATABLE-READ
可重复读级别解决了“不可重复读”及“幻读”问题,就是在同一个事务执行期间前后看到的数据必须一致,MySQL默认使用这个级别。简单说就是在同一个事务中发出同一个SELECT语句两次或更多次,那么产生的结果数据集总是相同的。因此,使用可重复读隔离级别的事务可以多次检索同一行集,并对它们执行任意操作,直到提交或回滚操作终止该事务。
现代数据库都使用 MVCC 技术实现了读不加锁,在 MySQL REPESTABLE-READ 隔离级别同样使用 MVCC 技术实现了读不加锁,基于 MVCC 的读操作称之为快照读(一致性读),并且在此基础上解决了快照读的“不可重复读”和“幻读”问题。
由于 MySQL MVCC 实现机制的不同,所以除了快照读,还有一种读称之为当前读,对于 update、insert、delete 都是采用当前读的模式,并且 select 语句带有 lock in share mode 或 for update 选项也是当前读。当前读对读取到的记录加行锁,在 RR 隔离级别同时对读取的范围加锁,也就是说新的满足查询条件的记录不能够插入 (由间隙锁保证),所以解决了当前读的“不可重复读”及“幻读”现象。
对于“不可重复读”及“幻读”问题,有时候很容易搞混淆。但从定义上来看,“不可重复读”主要针对update操作,对上一次读到的数据再次读取时发生了改变;而“幻读”主要针对insert及delete操作,对上一次读取到的数据条数变多或变少了。
实例
事务A:修改表,id=1的记录,不提交事务
|
1 2 3 4 |
mysql> set session transaction isolation level REPEATABLE-READ; mysql> select @@TX_isolation \G *************************** 1. row *************************** @@TX_isolation: READ-COMMITTED |
|
1 2 |
mysql> start transaction; mysql> update money set price=2000 where id=1; |
事务B:查看表
|
1 2 3 4 5 6 7 8 |
mysql> start transaction; mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 1000 *************************** 2. row *************************** id: 2 price: 1000 |
事务A:提交数据
|
1 |
mysql> commit; |
事务A:读取数据,发现就算事务A提交了数据,事务B也不会读取到事务更新的新数据
|
1 2 3 4 5 6 7 |
mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 1000 *************************** 2. row *************************** id: 2 price: 1000 |
PS:RR级别使用了MVCC机制,每次读取数据即为事务开始时数据的快照版本。
- READ-COMMITTED
在这个级别,能满足前面提到的隔离性的简单定义:一个事务开始时,只能“看见”已经提交的事务所做的修改。换句话说,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的,只有事务提交之后才对于其他事务可见。这个级别有时候也叫“不可重复读(non-repeatable read)”,因为两次执行同样的查询,可能会得到不一样的结果。为什么会出现“不可重复读”问题呢?从下面的分析中找答案。
RC隔离级别,针对当前读(还有快照读)保证对读取到的记录加读锁 (记录锁)。因为在RC的事务隔离级别下,除了唯一性的约束检查和外键约束的检查需要Gap Lock外,InnoDB存储引擎不会使用Gap Lock,所以会产生“不可重复读”问题。而不可重复读会破坏事务隔离性要求,也就是一个事务的修改操作对其他事务可见了。
实例
事务A:修改表,id=1的记录,不提交事务
|
1 2 3 4 |
mysql> set session transaction isolation level read committed; mysql> select @@TX_isolation \G *************************** 1. row *************************** @@TX_isolation: READ-COMMITTED |
|
1 2 3 4 5 6 7 8 9 10 |
mysql> start transaction; mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 1000 *************************** 2. row *************************** id: 2 price: 1000 mysql> update money set price=2000 where id=1; |
事务B: 查看表,并没有发生变化
|
1 2 3 4 |
mysql> set session transaction isolation level read committed; mysql> select @@TX_isolation \G *************************** 1. row *************************** @@TX_isolation: READ-COMMITTED |
|
1 2 3 4 5 6 7 8 |
mysql> start transaction; mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 1000 *************************** 2. row *************************** id: 2 price: 1000 |
事务A: 提交事务
|
1 |
mysql> commit; |
事务B: 查看数据,id=1的记录已经发生变化
|
1 2 3 4 5 6 7 |
mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 2000 *************************** 2. row *************************** id: 2 price: 1000 |
PS:RC级别使用了MVCC机制,即发生并行写读时,那么数据读取时就会使用快照读而不是当前读。
另外,使用这个事务隔离级别需要注意的一些问题,如二进制日志之只能够使用ROW(或MIXED)格式,如果使用STATEMENT会导致主从不一致的问题。接下来,通过一个实例看看RC隔离级别下为什么要用ROW格式(二进制日志要开启)?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
mysql> set tx_isolation='read-committed'; Query OK, 0 rows affected (0.01 sec) mysql> show session variables like 'tx_isolation'; +---------------+----------------+ | Variable_name | Value | +---------------+----------------+ | tx_isolation | READ-COMMITTED | +---------------+----------------+ 1 row in set (0.00 sec) mysql> show session variables like 'binlog_format'; +---------------+-----------+ | Variable_name | Value | +---------------+-----------+ | binlog_format | STATEMENT | +---------------+-----------+ 1 row in set (0.00 sec) mysql> insert into money values (10,1000); ERROR 1665 (HY000): Cannot execute statement: impossible to write to binary log since BINLOG_FORMAT = STATEMENT and at least one table uses a storage engine limited to row-based logging. InnoDB is limited to row-logging when transaction isolation level is READ COMMITTED or READ UNCOMMITTED. |
根据上述实验证明,如果当你隔离级别为RC,二进制格式为STATEMENT时,插入数据就会报错。为什么呢?那是因为RC隔离级别会导致“不可重复读”和“幻读”的问题,也就是说一个事务可以读取到另一个事务已经提交的数据。其中“幻读”问题,如果主从复制是基于STATEMENT格式的话,会导致主从数据不一致的情况,因为STATEMENT是基于SQL语句的复制模式,如下实验。
在Master主机上的操作如下:
事务A:删除id<=5的数据
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
mysql> set tx_isolation='read-committed'; Query OK, 0 rows affected (0.00 sec) mysql> select * from money; +----+-------+ | id | price | +----+-------+ | 1 | 3000 | | 2 | 3000 | | 4 | 3000 | | 5 | 3000 | +----+-------+ 4 rows in set (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> delete from money where id <=5; Query OK, 4 rows affected (0.04 sec) |
事务B:插入id=3的数据
|
1 2 3 4 5 6 7 8 9 10 11 |
mysql> set tx_isolation='read-committed'; Query OK, 0 rows affected (0.00 sec) mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> insert into blog.money values(3,3000); Query OK, 1 row affected (0.00 sec) mysql> COMMIT; Query OK, 0 rows affected (0.02 sec) |
事务A:提交事务
|
1 2 3 4 5 6 7 8 9 10 |
mysql> commit; Query OK, 0 rows affected (0.01 sec) mysql> select * from money; +----+-------+ | id | price | +----+-------+ | 3 | 3000 | +----+-------+ 1 row in set (0.00 sec) |
但是在Slave上看到的结果是:
|
1 2 |
mysql> select * from money; empty set (0.00 sec) |
最后我们发现在Master上money表中会还有一条事务2插入的数据并没有被后提交的事务所删除,这里先说一下由于在READ COMMITTED隔离级别下,事务没有使用gap lock进行锁定,因此用户在事务2中可以在小于等于5的范围内插入一条记录。STATEMENT格式记录的是Master上产生的SQL语句,因此在Master服务器上执行的顺序为先删后插,但是在Slave上STATEMENT格式记录的话执行时的顺序确是先插后删,逻辑顺序上产生了不一致,所以Master上money表中还有一条数据,而Slave上money表中却不会有数据。解决这个主从不一致的问题即使用RR隔离级别即可,因为RR级别使用gap lock,不会允许事务2插入数据的。
- READ-UNCOMMITTED
在这个级别,只加写锁,读不加锁。那么就会产生这三种情况:读读可以并行、读写可以并行、写读可以并行(只有写写不可以并行)。所以在这个级别,一个事务的修改,即使没有提交,对其他事务也都是可见的。一个事务可以读取另一个事务未提交的数据,这也被称为“脏读(dirty read)”,同样破坏了事务隔离性要求,一个事务的修改对其他事务可见了。这个级别会导致很多问题,如一个事务可以读取到另一个事务的中间状态,且从性能上来说,READ UNCOMMITTED不会比其他的级别好太多,但却缺乏其他级别的很多好处,除非真的有非常必要的理由,在实际应用中一般很少使用。
实例
建立表
|
1 2 3 4 5 |
create database bank; use bank; create table money(id INT NOT NULL PRIMARY KEY,price INT NOT NULL) engine=innodb; insert into money(id,price) values(1,1000); insert into money(id,price) values(2,1000); |
事务A:更新一条记录
|
1 2 3 4 5 6 7 8 9 10 11 12 |
mysql> set session transaction isolation level read uncommitted; mysql> select @@TX_ISOLATION \G *************************** 1. row *************************** @@TX_ISOLATION: READ-UNCOMMITTED mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 1000 *************************** 2. row *************************** id: 2 price: 1000 |
|
1 2 |
mysql> start transaction; mysql> update money set price=2000 where id=1; |
事务B:查看数据以及发生变化,此时事务A还没有提交数据
|
1 2 3 4 |
mysql> set session transaction isolation level read uncommitted; mysql> select @@TX_ISOLATION \G *************************** 1. row *************************** @@TX_ISOLATION: READ-UNCOMMITTED<strong> </strong> |
|
1 2 3 4 5 6 7 8 |
mysql> start transaction; mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 2000 *************************** 2. row *************************** id: 2 price: 1000 |
事务A:进行事务回滚
|
1 |
mysql> rollback; |
事务B:查看数据已经跟上一次查看不一样了,这就是读“脏”数据
|
1 2 3 4 5 6 7 |
mysql> select * from money \G *************************** 1. row *************************** id: 1 price: 1000 *************************** 2. row *************************** id: 2 price: 1000 |
PS:由此发现在RU级别会产生读“脏”数据。
总结来说,存在即合理,哪个隔离级别都有它自己的使用场景,你要根据自己的业务情况来定。我想你可能会问那什么时候需要“可重复读”的场景呢?我们来看一个数据校对逻辑的案例。
假设你在管理一个个人银行账户表。一个表存了每个月月底的余额,一个表存了账单明细。这时候你要做数据校对,也就是判断上个月的余额和当前余额的差额,是否与本月的账单明细一致。你一定希望在校对过程中,即使有用户发生了一笔新的交易,也不影响你的校对结果。
这时候使用“可重复读”隔离级别就很方便。事务启动时的视图可以认为是静态的,不受其他事务更新的影响。
二、事务隔离实现
理解了事务的隔离级别,我们再来看看事务隔离具体是怎么实现的。这里我们展开说明“可重复读”。
在实现上,数据库里面会创建一个视图(read-view),访问的时候以视图的逻辑结果为准。在“可重复读”隔离级别下,这个视图是在事务启动时创建的,整个事务存在期间都用这个视图,即使有其他事务修改了数据,事务中看到的数据仍然跟在启动时看到的一样。在“读提交”隔离级别下,这个视图是在每个 SQL 语句开始执行的时候创建的。这里需要注意的是,“读未提交”隔离级别下直接返回记录上的最新值,没有视图概念;而“串行化”隔离级别下直接用加锁的方式来避免并行访问。
在 MySQL 中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值。
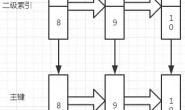
假设一个值从 1 被按顺序改成了 2、3、4,在回滚日志里面就会有类似下面的记录。

当前值是 4,但是在查询这条记录的时候,不同时刻启动的事务会有不同的 read-view。如图中看到的,在视图 A、B、C 里面,这一个记录的值分别是 1、2、4,同一条记录在系统中可以存在多个版本,就是数据库的多版本并发控制(MVCC)。对于 read-view A,要得到 1,就必须将当前值依次执行图中所有的回滚操作得到。
同时你会发现,即使现在有另外一个事务正在将 4 改成 5,这个事务跟 read-view A、B、C 对应的事务是不会冲突的。你一定会问,回滚日志总不能一直保留吧,什么时候删除呢?答案是,在不需要的时候才删除。也就是说,系统会判断,当没有事务再需要用到这些回滚日志时,回滚日志会被删除。 什么时候才不需要了呢?就是当系统里没有比这个回滚日志更早的 read-view 的时候。
基于上面的说明,我们来讨论一下为什么建议你尽量不要使用长事务。
长事务意味着系统里面会存在很老的事务视图。由于这些事务随时可能访问数据库里面的任何数据,所以这个事务提交之前,数据库里面它可能用到的回滚记录都必须保留,这就会导致大量占用存储空间。
在 MySQL 5.5 及以前的版本,回滚日志是跟数据字典一起放在 ibdata 文件里的,即使长事务最终提交,回滚段被清理,文件也不会变小,当然这个问题在 MySQL 5.7 中已经彻底解决了。我见过数据只有 20GB,而回滚段有 200GB 的库。最终只好为了清理回滚段,重建整个库。 除了对回滚段的影响,长事务还占用锁资源,也可能拖垮整个库。
你可以在 information_schema 库的 innodb_trx 这个表中查询长事务,比如下面这个语句,用于查找持续时间超过 60s 的事务。
|
1 2 |
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60 |
各个具体数据库并不一定完全实现了上述4个隔离级别,例如:
Oracle只提供READ COMMITTED和SERIALIZABLE两个标准隔离级别,另外还提供自己定义的Read only隔离级别;
SQL Server除支持上述ISO/ANSI SQL92定义的4个隔离级别外,还支持一个叫做“快照读”的隔离级别,但严格来说它是一个用MVCC机制实现的SERIALIZABLE隔离级别。
MySQL支持全部4个隔离级别,其默认级别为Repeatable read,但在具体实现时,有一些特点,比如在一些隔离级别下是采用MVCC一致性读。
国产数据库DM也支持所有级别,其默认级别为READ COMMITTED。
最后好像又有人提出了“无锁”编程的概念,真是学无止尽啊,妈了鸡,学的累死了。
https://www.cnblogs.com/xuwc/p/13873293.html