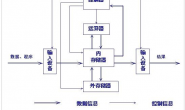
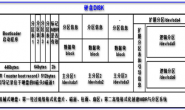
https://www.zhihu.com/question/37550908/answer/72479774 https://zhuanlan.zhihu.com/paogenjiudi https://www.zhihu.com/question/24340504 https://mp.weixin.qq.com/s/ckWzRIfNdEy5yZt_7IKqkA 如果您觉得本站对你有帮助,那么可以支付宝扫码捐助以帮助本站更好地发展,在此谢过。 喜欢 (3)赏[资助本站您就扫码 谢谢]分享 (0)