一、堆表和索引组织表
NOTE
堆表也可以称之为 HOT,索引组织表也可以称之为 IOT,下面没有特别说明,两者都是一个意思。
堆(heap)组织表数据行在堆中存储,没有任何特定顺序,向一个全新的没有做过更新和删除的堆中插入一行时候,总是 append 到堆表文件的最后一页当中。因为不用考虑排序,所以插入速度会比较快。
但是要查找符合某个条件的记录,就必须得读取全部的记录以便筛选。而这个时候为了加快查询速度,索引就出现了,索引是针对少量特定字段的值拿出来进行排序存储,存储索引 key 以及数据行在堆表上面的绝对位置(页号,页内偏移),而因为索引是有序的,所以就会很容易通过索引查询到具体的记录位置(普遍使用二分查找法),然后再根据记录位置直接从表中读取该记录。同时因为索引的字段较少,所以索引通常会比其基表小得多。
从上面通过索引访问表记录的方式可以看出,当要访问的数据量较大时,通过每一条记录的位置去访问原始记录,每一条符合条件的记录都需要经过索引访问后再访问基表这样一个复杂的过程,这会花费很多时间。同样,如果不经过索引而直接查询表,也可能因为表字段太多,记录较大的情况下把全部的数据读取进来,这也会花费很多时间。
那怎么办呢?这个时候就会想到,如果表中数据本身就是有序的,这样查询表的时候就可以快速的找到符合条件的记录位置,而很容易判断符合条件记录的位置,这样只需要读取一小部分数据出来就可以了,不需要全表记录都读取出来进行判断。索引组织表就这样产生了,当然索引表中插入,更新的时候可能会因为需要排序而将数据重组,这时候数据插入或更新速度会比堆组织表慢一些。如果堆组织表上有索引,那么对堆组织表的插入也会因为要修改索引而变慢。
二、堆表和索引组织表的比较
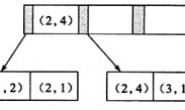
所以,堆表的特点就是索引和数据分开,所有索引都是二级索引,或叫辅助索引。所以主键索引也是二级索引,没有完整记录,区别只有唯一或非唯一。索引中存储的是 key 与指针,指针指向具体数据记录。当然,查找 key 的算法都是一样的,使用二分查找,也叫书签查找。
跟索引组织表相比,堆表有什么好处呢?其实主要就是通过主键或二级索引查询,开销是一样的。都是通过先找到key,然后定位到数据。而索引组织表,由于二级索引是指向主键,所以查询二级索引需要先定位到 key,然后拿到主键 id,还要根据主键 id 再次通过二分查找定位到真正的数据页。当然,索引组织表通过主键查询开销与堆是一样的。从索引组织表的工作方式可以看出,索引组织表必须要有主键,如果非显式创建,InnoDB 存储引擎会默认创建一个 ROWID 当做主键;而堆表则无强制要求。
这就是经常有文章说 MyISAM 比 InnoDB 快的原因吧,但这个说法并不完全正确,索引组织表由于索引项和数据存储在一起,且 InnoDB 聚集索引各个叶子节点之间都是同过双向链表组织,且都是根据主键逻辑顺序存放,所以无论是基于主键的等值查询还是范围查询都能大大节省磁盘访问时间。特别对于范围查询,只需要定位到开始 key 的位置,就可以顺着这个位置扫描到结束key即可。如下 SQL 语句:
|
1 |
select * from table where id between 1000 and 2000 |
根据主键查时,假设主键 b+tree 高度是 3,每个叶子节点能存储 100 条记录,1000 条记录需要 10 个页。那么这个查询只需要大概 2 + 9 次 io 开销。
另外由于索引组织表的特性带来另外一个优点,举例来说,假设表 tab1(a int primary key, b int) 有两行 R1(1,2) 和 R2(2,3),那么如果 tab1 的主键索引是聚簇的 — 例如 InnoDB 就是这样 — 那么 R1 和 R2 由于其主键值是相邻的,所以在磁盘上面它们也是相邻存放的。也就是说 R1 和 R2 大概率在同一个磁盘页面上面(也可能是 R1 刚好位于一个 leaf page 的最后一行,而 R2 刚好是下一个 leaf page 的第一行,在这种情况下,我们仍然说 R1 和 R2 是相邻的),这样一次逻辑 io 查询的数据行命中率可能是 90%。
而堆表的索引只存储索引 key 以及数据行在堆表上面的绝对位置(页号,页内偏移),这样,主键值相邻的两行,它们在堆表的数据行经常位于不同的页面,除非这个表很少更新删除,并且插入的时候是按照主键值递增的顺序做 ‘append’ 型的插入的,不会后续在 pk 的已存在范围做插入。大多数 OLTP 类应用的逻辑无法满足这样苛刻的要求。这样,如果数据和查询具有局部性(通常如此),那么就无法享受到聚集索引带来的性能优势。
当然了,有序的代价也是很大的,无法 ‘append’ 插入,涉及数据重组,也就是索引页分裂与均衡。另外,如果对于索引组织表范围查询走的是二级索引,那么开销是多大呢?
如下 SQL 语句,同样是查询二级索引 1000 条记录。
|
1 |
select * from table where date >= 1990 limit 1000 |
这里假设二级索引 b+tree 高度也是 3,假设每个页子节点能存储200条键值对,这里的开销就变成了 3 + 4 + 3000 次 IO 开销了(其中3是定位到开始值的数据页,4 是扫描二级索引 1000 条数据需要扫描的页,3000 = 3*1000 表示回表到主键 1000 次产生的 IO)。这种方式也称之为回表,从二级索引回到主键。所以在这种情况下,InnoDB 很多时候都选择了直接扫描主键,也就是全表扫描,其代价可能比回表开销更小,比如在表数据页小于回表所产生的 io 次数时,因为全表扫描每个页也就一次 io 而已。这在 MySQL 5.6 之前都是这么工作的,但在 MySQL 5.6 有了 MRR 技术后,这种情况就改善了很多。
MRR 简单来说就是为每个线程开辟了一块内存空间,由 read_rnd_buffer_size 参数设置,默认 32M,把二级索引查询结果放到这块空间,并且做排序,然后利用排序后的数据进行回表,就是顺序的了。如果 mrr 内存够大,那么最快可以一次回表就拿到所有数据。当然mrr优化主要是针对磁盘的,磁盘越慢效果越好。如果你的 buffer pool 可以装下所有表数据,那么 MRR 效果其实也不大了,但一般这种情况很少。
那么堆表的缺点是什么呢?
这里我们想一下,由于堆表的索引只存储索引 key 以及数据行在堆表上面的绝对位置(页号,页内偏移),如果这行记录发生了更新,并且不能原地更新,需要进行迁移,那么就会发生一个情况,堆表所有索引都需要修改,指向新的行位置。而索引组织表就不需要这个开销,更新只会新插入变化了的索引 key,不变的索引 key 不需要新插入,只有当主键发生更改才需要对应修改其他二级索引,通常主键也不会更新,所以这也就是索引组织表更新效率更高的由来。
但一般使用堆表的数据库都不会直接这么更新,代价太大了。而是会在数据页预留一些空间,当遇见不能原地更新的记录时,就会在这个页中新插入一条更新后的记录,然后在这个页中做一个指针把老记录指向新纪录,这样就不用更新索引信息了。当然,如果你这个页中没有空闲空间可以插入新的记录,那么还是需要做行迁移,然后更新所有索引。