一、GTID与MHA
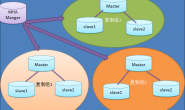
MHA是被广泛使用MySQL HA组件,MHA 0.56以后支持基于GTID的复制。 MHA在failover时会自动判断是否是GTID based failover,需要满足下面3个条件即为GTID based failover。
- 所有节点gtid_mode=1
- 所有节点Executed_Gtid_Set不为空
- 至少一个节点Auto_Position=1
和之前的基于binlog文件位置的复制相比,基于GTID复制下,MHA在故障切换时的变化主要如下:
基于binlog文件位置的复制
- 在Master宕机后会尝试从Master上拷贝binlog日志进行补偿。
- 如果候选Master不拥有最新的relay log,会从拥有最新relay log的Slave上生成差异的binlog传送到候选Master并实施补偿。
- 新Master的日志补偿完成后,同样采用应用差异binlog的方式将其它Slave和新Master同步后再change master到新Master。
基于GTID的复制
- 如果候选Master不拥有最新的relay log,让候选Master连上拥有最新relay log的Salve进行补偿。
- 尝试从binlog server上拉取缺失的binlog并应用。
- 新Master的数据同步到最新后,让其它的Slave连上新Master并等待数据完成同步。并且可以给masterha_master_switch传入–wait_until_gtid_in_sync=1参数使其不等其它Slave完成数据同步,以加快切换速度。
GTID模式下MHA不会尝试从旧Master上拷贝binlog日志进行补偿,所以在MySQL进程Crash而OS仍然健康的情况下,应尽量不要做主备切换而是原地重启MySQL,除非有其它能确保切换后不丢数据的措施。但在GTID模式下MHA支持在复制拓扑中增加一个或多个 binlog server 起到日志补偿的作用,非GTID模式下即使配置了binlog server 也会被MHA忽略。
日志补偿可以说是MHA中最复杂也最精华的部分,有了GTID后故障切换变得更简单了,不再需要原本复杂的binlog日志解析和补偿。所以Oracle官方推出了只支持GTID复制的切换工具mysqlfailover,在GTID的帮助下,我们有更多靠谱的HA工具可以选择。
二、搭建主从复制环境(GTID异步复制)
注意:所有slave上的replicate-ignore-db设置必须相同,MHA在启动时候会检测过滤规则,如果过滤规则不同,MHA不启动监控和故障转移。
在整个复制集群中,这边都开启了GTID,关于GTID请看其他章节。从MHA 0.57开始,就可以支持GTID了。关于MySQL的安装配置,GTID配置等操作可以看MySQL基于GTID的复制实现详解。下面只给出一些复制相关操作。
1)在mysql01上创建复制用户
|
1 2 |
mysql> grant replication slave on *.* to 'mysql_slave'@'%' identified by '123456'; mysql> flush privileges; |
2)在mysql02上连接mysql01
|
1 2 |
mysql> CHANGE MASTER TO MASTER_HOST='10.99.73.9',MASTER_PORT=3306,MASTER_USER='mysql_slave',MASTER_PASSWORD='123456', MASTER_AUTO_POSITION=1; mysql> start slave; |
3)在mysql03上连接mysql01
|
1 2 |
mysql> CHANGE MASTER TO MASTER_HOST='10.99.73.9',MASTER_PORT=3306,MASTER_USER='mysql_slave',MASTER_PASSWORD='123456', MASTER_AUTO_POSITION=1; mysql> start slave; |
4)两台slave服务器设置read_only(从库对外提供读服务,只所以没有写进配置文件,是因为随时slave会提升为master)
|
1 2 |
mysql> set global read_only=1; mysql> set global read_only=1; |
5)创建监控用户(在master上执行,也就是10.99.73.9)
|
1 2 |
mysql> grant all privileges on *.* to 'mha'@'%' identified by '123456'; mysql> flush privileges; |
到这里整个复制集群环境已经搭建完毕,剩下的就是配置MHA软件了。
三、测试MHA
MHA启动配置
对于GTID模式,要注意,如果数据库没有执行过一条事务,那么show slave status中即没有执行过任何Executed_Gtid_Set,MHA会认为是非GTID模式。
另外,对于GTID模式需要配置binlog server。如果不配置,即使在old master SSH可达的情况下,它也不会去save binlog,所以GTID和non-GTID模式的区别比较大。解决的方案就是: 配置Binlog Server。
配置如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
[root@mha ~]# cat /etc/masterha/app1.cnf [server default] manager_log=/var/log/masterha/app1/manager.log manager_workdir=/var/log/masterha/app1 master_binlog_dir=/data/mysql/3306/log/binlog password=123456 ping_interval=3 remote_workdir=/data/mysql/mha repl_password=123456 repl_user=mysql_slave shutdown_script="" ssh_user=root user=mha master_ip_failover_script=/usr/local/bin/master_ip_failover master_ip_online_change_script=/usr/local/bin/master_ip_online_change report_script=/usr/local/bin/send_report [server1] candidate_master=1 hostname=10.99.73.9 port=3306 [server2] candidate_master=1 hostname=10.99.73.10 port=3306 [server3] hostname=10.99.73.11 no_master=1 port=3306 [binlog1] hostname=10.99.73.9 hostname=10.99.73.10 hostname=10.99.73.11 |
注意:当主从复制为GTID时,需要设置binlog1,这里的binlog1既可以设置master为binlog server,也可以设置其他专用的binlog server。
检查主从复制状态
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[root@mha ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf 10.99.73.9(10.99.73.9:3306) (current master) +--10.99.73.10(10.99.73.10:3306) +--10.99.73.11(10.99.73.11:3306) Tue Feb 21 15:48:26 2017 - [info] Checking replication health on 10.99.73.10.. Tue Feb 21 15:48:26 2017 - [info] ok. Tue Feb 21 15:48:26 2017 - [info] Checking replication health on 10.99.73.11.. Tue Feb 21 15:48:26 2017 - [info] ok. Tue Feb 21 15:48:26 2017 - [warning] master_ip_failover_script is not defined. Tue Feb 21 15:48:26 2017 - [warning] shutdown_script is not defined. Tue Feb 21 15:48:26 2017 - [info] Got exit code 0 (Not master dead). MySQL Replication Health is OK. |
启动MHA
|
1 |
[root@mha ~]# nohup masterha_manager --conf=/etc/masterha/app1.cnf --remove_dead_master_conf --ignore_last_failover & |
启动日志信息
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
Started automated(non-interactive) failover. Got Error so couldn't continue failover from here. Mon Feb 20 18:27:54 2017 - [info] Sending mail.. Unknown option: conf Tue Feb 21 16:01:22 2017 - [info] MHA::MasterMonitor version 0.57. Tue Feb 21 16:01:22 2017 - [info] GTID failover mode = 1 Tue Feb 21 16:01:22 2017 - [info] Dead Servers: Tue Feb 21 16:01:22 2017 - [info] Alive Servers: Tue Feb 21 16:01:22 2017 - [info] 10.99.73.9(10.99.73.9:3306) Tue Feb 21 16:01:22 2017 - [info] 10.99.73.10(10.99.73.10:3306) Tue Feb 21 16:01:22 2017 - [info] 10.99.73.11(10.99.73.11:3306) Tue Feb 21 16:01:22 2017 - [info] Alive Slaves: Tue Feb 21 16:01:22 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 16:01:22 2017 - [info] GTID ON Tue Feb 21 16:01:22 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 16:01:22 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 16:01:22 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 16:01:22 2017 - [info] GTID ON Tue Feb 21 16:01:22 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 16:01:22 2017 - [info] Not candidate for the new Master (no_master is set) Tue Feb 21 16:01:22 2017 - [info] Current Alive Master: 10.99.73.9(10.99.73.9:3306) Tue Feb 21 16:01:22 2017 - [info] Checking slave configurations.. Tue Feb 21 16:01:22 2017 - [info] Checking replication filtering settings.. Tue Feb 21 16:01:22 2017 - [info] binlog_do_db= , binlog_ignore_db= Tue Feb 21 16:01:22 2017 - [info] Replication filtering check ok. Tue Feb 21 16:01:22 2017 - [info] GTID (with auto-pos) is supported. Skipping all SSH and Node package checking. Tue Feb 21 16:01:22 2017 - [info] HealthCheck: SSH to 10.99.73.9 is reachable. Tue Feb 21 16:01:22 2017 - [info] Binlog server 10.99.73.9 is reachable. Tue Feb 21 16:01:22 2017 - [info] Checking recovery script configurations on 10.99.73.9(10.99.73.9:3306).. Tue Feb 21 16:01:22 2017 - [info] Executing command: save_binary_logs --command=test --start_pos=4 --binlog_dir=/data/mysql/3306/log/binlog --output_file=/data/mysql/mha/save_binary_logs_test --manager_version=0.57 --start_file=mysql-bin.000002 Tue Feb 21 16:01:22 2017 - [info] Connecting to root@10.99.73.9(10.99.73.9:22).. Creating /data/mysql/mha if not exists.. ok. Checking output directory is accessible or not.. ok. Binlog found at /data/mysql/3306/log/binlog, up to mysql-bin.000002 Tue Feb 21 16:01:22 2017 - [info] Binlog setting check done. Tue Feb 21 16:01:22 2017 - [info] Checking SSH publickey authentication settings on the current master.. Tue Feb 21 16:01:22 2017 - [info] HealthCheck: SSH to 10.99.73.9 is reachable. Tue Feb 21 16:01:22 2017 - [info] 10.99.73.9(10.99.73.9:3306) (current master) +--10.99.73.10(10.99.73.10:3306) +--10.99.73.11(10.99.73.11:3306) Tue Feb 21 16:01:22 2017 - [warning] master_ip_failover_script is not defined. Tue Feb 21 16:01:22 2017 - [warning] shutdown_script is not defined. Tue Feb 21 16:01:22 2017 - [info] Set master ping interval 3 seconds. Tue Feb 21 16:01:22 2017 - [info] Set secondary check script: /usr/local/bin/masterha_secondary_check -s mysql02 -s mysql03 --user=root --master_host=mysql01 --master_ip=10.99.73.9 --master_port=3306 Tue Feb 21 16:01:22 2017 - [info] Starting ping health check on 10.99.73.9(10.99.73.9:3306).. Tue Feb 21 16:01:22 2017 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond.. |
一、测试自动Failover(主要测试new master是补谁的日志)
必须先启动MHA Manager,否则无法自动切换,当然手动切换不需要开启MHA Manager监控。各位童鞋请参考前面启动MHA Manager。
自动failover模拟测试的操作步骤如下。
1)使用sysbench生成测试数据(使用yum快速安装)
|
1 |
$ yum install sysbench -y |
在主库(10.99.73.9)上进行sysbench数据生成,在sbtest库下生成sbtest表,共100W记录。
|
1 |
mysql> create database sbtest charset utf8mb4; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ sysbench /usr/share/sysbench/oltp_read_only.lua \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user=mha \ --mysql-password=123456 \ --mysql-socket=/data/mysql/3306/mysql.sock \ --mysql-db=sbtest \ --db-driver=mysql \ --tables=1 \ --table-size=1000000 \ --report-interval=10 \ --threads=128 \ --time=120 \ prepare |
如果是需要产生大量的binlog,使用sysbench模拟压测,持续时间为2分钟,产生大量的binlog。使用如下语句(这里我们不使用):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ sysbench /usr/share/sysbench/oltp_read_only.lua \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user=mha \ --mysql-password=123456 \ --mysql-socket=/data/mysql/3306/mysql.sock \ --mysql-db=sbtest \ --db-driver=mysql \ --tables=1 \ --table-size=1000000 \ --report-interval=10 \ --threads=128 \ --time=120 \ run |
2)停掉slave io线程(10.99.73.10)
一定要在master执行sysbench结束之前停掉slave io线程,这样我们才可以模拟查看当10.99.73.10成为new master之后是否会同步old master的binlog。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mysql> stop slave io_thread; Query OK, 0 rows affected (0.05 sec) mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 860000 | +----------+ 1 row in set (0.30 sec) mysql> show master status; +------------------+----------+--------------+------------------+-------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------------------------------+ | mysql-bin.000001 | 53571295 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-89 | +------------------+----------+--------------+------------------+-------------------------------------------+ 1 row in set (0.00 sec) |
另外一台slave我们没有停止io线程,所以还在继续接收执行日志。
3)停掉slave io线程(10.99.73.11)
你可以一直使用show slave status命令查看当前此slave的状态,只要比10.99.73.10同步的数据多就可以停掉io线程了,但是记住不要把master的数据完全同步完了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mysql> stop slave io_thread; Query OK, 0 rows affected (0.03 sec) mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 900000 | +----------+ 1 row in set (0.28 sec) mysql> show master status; +------------------+----------+--------------+------------------+-------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------------------------------+ | mysql-bin.000001 | 56062943 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-93 | +------------------+----------+--------------+------------------+-------------------------------------------+ 1 row in set (0.00 sec) |
4)杀掉主库MySQL进程,模拟主库发生故障,进行自动failover操作。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (0.35 sec) mysql> show master status; +------------------+-----------+--------------+------------------+--------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+-----------+--------------+------------------+--------------------------------------------+ | mysql-bin.000001 | 123299163 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 | +------------------+-----------+--------------+------------------+--------------------------------------------+ 1 row in set (0.00 sec) |
|
1 |
$ mysqladmin -S /data/mysql/3306/mysql.sock shutdown |
PS:可以看出master是100万数据,slave(10.99.73.10)只有86万数据,而slave(10.99.73.11)有90万数据,下面看整个MHA的切换过程。
5)查看MHA切换日志,了解整个切换过程,在10.99.73.7上查看日志。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 |
[root@mha ~]# cat /var/log/masterha/app1/manager.log Tue Feb 21 17:46:11 2017 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query) Tue Feb 21 17:46:11 2017 - [info] Executing secondary network check script: /usr/local/bin/masterha_secondary_check -s mysql02 -s mysql03 --user=root --master_host=mysql01 --master_ip=10.99.73.9 --master_port=3306 --user=root --master_host=10.99.73.9 --master_ip=10.99.73.9 --master_port=3306 --master_user=mha --master_password=123456 --ping_type=SELECT Tue Feb 21 17:46:11 2017 - [info] Executing SSH check script: exit 0 Tue Feb 21 17:46:11 2017 - [info] HealthCheck: SSH to 10.99.73.9 is reachable. Monitoring server mysql02 is reachable, Master is not reachable from mysql02. OK. Monitoring server mysql03 is reachable, Master is not reachable from mysql03. OK. Tue Feb 21 17:46:11 2017 - [info] Master is not reachable from all other monitoring servers. Failover should start. Tue Feb 21 17:46:14 2017 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.99.73.9' (111)) Tue Feb 21 17:46:14 2017 - [warning] Connection failed 2 time(s).. Tue Feb 21 17:46:17 2017 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.99.73.9' (111)) Tue Feb 21 17:46:17 2017 - [warning] Connection failed 3 time(s).. Tue Feb 21 17:46:20 2017 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '10.99.73.9' (111)) Tue Feb 21 17:46:20 2017 - [warning] Connection failed 4 time(s).. Tue Feb 21 17:46:20 2017 - [warning] Master is not reachable from health checker! Tue Feb 21 17:46:20 2017 - [warning] Master 10.99.73.9(10.99.73.9:3306) is not reachable! Tue Feb 21 17:46:20 2017 - [warning] SSH is reachable. Tue Feb 21 17:46:20 2017 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /etc/masterha/app1.cnf again, and trying to connect to all servers to check server status.. Tue Feb 21 17:46:20 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Feb 21 17:46:20 2017 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Tue Feb 21 17:46:20 2017 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Tue Feb 21 17:46:20 2017 - [info] GTID failover mode = 1 Tue Feb 21 17:46:20 2017 - [info] Dead Servers: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Alive Servers: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.10(10.99.73.10:3306) Tue Feb 21 17:46:20 2017 - [info] 10.99.73.11(10.99.73.11:3306) Tue Feb 21 17:46:20 2017 - [info] Alive Slaves: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 17:46:20 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Not candidate for the new Master (no_master is set) Tue Feb 21 17:46:20 2017 - [info] Checking slave configurations.. Tue Feb 21 17:46:20 2017 - [info] Checking replication filtering settings.. Tue Feb 21 17:46:20 2017 - [info] Replication filtering check ok. Tue Feb 21 17:46:20 2017 - [info] Master is down! Tue Feb 21 17:46:20 2017 - [info] Terminating monitoring script. Tue Feb 21 17:46:20 2017 - [info] Got exit code 20 (Master dead). Tue Feb 21 17:46:20 2017 - [info] MHA::MasterFailover version 0.57. Tue Feb 21 17:46:20 2017 - [info] Starting master failover. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] * Phase 1: Configuration Check Phase.. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] HealthCheck: SSH to 10.99.73.9 is reachable. Tue Feb 21 17:46:20 2017 - [info] Binlog server 10.99.73.9 is reachable. Tue Feb 21 17:46:20 2017 - [info] GTID failover mode = 1 Tue Feb 21 17:46:20 2017 - [info] Dead Servers: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Checking master reachability via MySQL(double check)... Tue Feb 21 17:46:20 2017 - [info] ok. Tue Feb 21 17:46:20 2017 - [info] Alive Servers: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.10(10.99.73.10:3306) Tue Feb 21 17:46:20 2017 - [info] 10.99.73.11(10.99.73.11:3306) Tue Feb 21 17:46:20 2017 - [info] Alive Slaves: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 17:46:20 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Not candidate for the new Master (no_master is set) Tue Feb 21 17:46:20 2017 - [info] Starting GTID based failover. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] ** Phase 1: Configuration Check Phase completed. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] * Phase 2: Dead Master Shutdown Phase.. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] Forcing shutdown so that applications never connect to the current master.. Tue Feb 21 17:46:20 2017 - [warning] master_ip_failover_script is not set. Skipping invalidating dead master IP address. Tue Feb 21 17:46:20 2017 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Tue Feb 21 17:46:20 2017 - [info] * Phase 2: Dead Master Shutdown Phase completed. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] * Phase 3: Master Recovery Phase.. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] The latest binary log file/position on all slaves is mysql-bin.000002:111856928 Tue Feb 21 17:46:20 2017 - [info] Retrieved Gtid Set: 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-93 Tue Feb 21 17:46:20 2017 - [info] Latest slaves (Slaves that received relay log files to the latest): Tue Feb 21 17:46:20 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Not candidate for the new Master (no_master is set) Tue Feb 21 17:46:20 2017 - [info] The oldest binary log file/position on all slaves is mysql-bin.000002:106037401 Tue Feb 21 17:46:20 2017 - [info] Retrieved Gtid Set: 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-89 Tue Feb 21 17:46:20 2017 - [info] Oldest slaves: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] * Phase 3.3: Determining New Master Phase.. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] Searching new master from slaves.. Tue Feb 21 17:46:20 2017 - [info] Candidate masters from the configuration file: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 17:46:20 2017 - [info] Non-candidate masters: Tue Feb 21 17:46:20 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 17:46:20 2017 - [info] GTID ON Tue Feb 21 17:46:20 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 17:46:20 2017 - [info] Not candidate for the new Master (no_master is set) Tue Feb 21 17:46:20 2017 - [info] Searching from candidate_master slaves which have received the latest relay log events.. Tue Feb 21 17:46:20 2017 - [info] Not found. Tue Feb 21 17:46:20 2017 - [info] Searching from all candidate_master slaves.. Tue Feb 21 17:46:20 2017 - [info] New master is 10.99.73.10(10.99.73.10:3306) Tue Feb 21 17:46:20 2017 - [info] Starting master failover.. Tue Feb 21 17:46:20 2017 - [info] From: 10.99.73.9(10.99.73.9:3306) (current master) +--10.99.73.10(10.99.73.10:3306) +--10.99.73.11(10.99.73.11:3306) To: 10.99.73.10(10.99.73.10:3306) (new master) +--10.99.73.11(10.99.73.11:3306) Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] * Phase 3.3: New Master Recovery Phase.. Tue Feb 21 17:46:20 2017 - [info] Tue Feb 21 17:46:20 2017 - [info] Waiting all logs to be applied.. Tue Feb 21 17:46:20 2017 - [info] done. Tue Feb 21 17:46:20 2017 - [info] Replicating from the latest slave 10.99.73.11(10.99.73.11:3306) and waiting to apply.. Tue Feb 21 17:46:20 2017 - [info] Waiting all logs to be applied on the latest slave.. Tue Feb 21 17:46:20 2017 - [info] Resetting slave 10.99.73.10(10.99.73.10:3306) and starting replication from the new master 10.99.73.11(10.99.73.11:3306).. Tue Feb 21 17:46:21 2017 - [info] Executed CHANGE MASTER. Tue Feb 21 17:46:21 2017 - [info] Slave started. Tue Feb 21 17:46:21 2017 - [info] Waiting to execute all relay logs on 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 17:46:21 2017 - [info] master_pos_wait(mysql-bin.000001:56062943) completed on 10.99.73.10(10.99.73.10:3306). Executed 5 events. Tue Feb 21 17:46:21 2017 - [info] done. Tue Feb 21 17:46:21 2017 - [info] done. Tue Feb 21 17:46:21 2017 - [info] -- Saving binlog from host 10.99.73.9 started, pid: 4018 Tue Feb 21 17:46:22 2017 - [info] Tue Feb 21 17:46:22 2017 - [info] Log messages from 10.99.73.9 ... Tue Feb 21 17:46:22 2017 - [info] Tue Feb 21 17:46:21 2017 - [info] Fetching binary logs from binlog server 10.99.73.9.. Tue Feb 21 17:46:21 2017 - [info] Executing binlog save command: save_binary_logs --command=save --start_file=mysql-bin.000002 --start_pos=110969333 --output_file=/data/mysql/mha/saved_binlog_binlog1_20170221174620.binlog --handle_raw_binlog=0 --skip_filter=1 --disable_log_bin=0 --manager_version=0.57 --oldest_version=5.7.17-log --binlog_dir=/data/mysql/3306/log/binlog Creating /data/mysql/mha if not exists.. ok. Concat binary/relay logs from mysql-bin.000002 pos 110969333 to mysql-bin.000002 EOF into /data/mysql/mha/saved_binlog_binlog1_20170221174620.binlog .. Concat succeeded. Tue Feb 21 17:46:22 2017 - [info] scp from root@10.99.73.9:/data/mysql/mha/saved_binlog_binlog1_20170221174620.binlog to local:/var/log/masterha/app1/saved_binlog_10.99.73.9_binlog1_20170221174620.binlog succeeded. Tue Feb 21 17:46:22 2017 - [info] End of log messages from 10.99.73.9. Tue Feb 21 17:46:22 2017 - [info] Saved mysqlbinlog size from 10.99.73.9 is 8506853 bytes. Tue Feb 21 17:46:22 2017 - [info] Applying differential binlog /var/log/masterha/app1/saved_binlog_10.99.73.9_binlog1_20170221174620.binlog .. Tue Feb 21 17:46:23 2017 - [info] Differential log apply from binlog server succeeded. Tue Feb 21 17:46:23 2017 - [info] Getting new master's binlog name and position.. Tue Feb 21 17:46:23 2017 - [info] mysql-bin.000001:62292113 Tue Feb 21 17:46:23 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.99.73.10', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='mysql_slave', MASTER_PASSWORD='xxx'; Tue Feb 21 17:46:23 2017 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000001, 62292113, 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 Tue Feb 21 17:46:23 2017 - [warning] master_ip_failover_script is not set. Skipping taking over new master IP address. Tue Feb 21 17:46:23 2017 - [info] Setting read_only=0 on 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 17:46:23 2017 - [info] ok. Tue Feb 21 17:46:23 2017 - [info] ** Finished master recovery successfully. Tue Feb 21 17:46:23 2017 - [info] * Phase 3: Master Recovery Phase completed. Tue Feb 21 17:46:23 2017 - [info] Tue Feb 21 17:46:23 2017 - [info] * Phase 4: Slaves Recovery Phase.. Tue Feb 21 17:46:23 2017 - [info] Tue Feb 21 17:46:23 2017 - [info] Tue Feb 21 17:46:23 2017 - [info] * Phase 4.1: Starting Slaves in parallel.. Tue Feb 21 17:46:23 2017 - [info] Tue Feb 21 17:46:23 2017 - [info] -- Slave recovery on host 10.99.73.11(10.99.73.11:3306) started, pid: 4037. Check tmp log /var/log/masterha/app1/10.99.73.11_3306_20170221174620.log if it takes time.. Tue Feb 21 17:46:24 2017 - [info] Tue Feb 21 17:46:24 2017 - [info] Log messages from 10.99.73.11 ... Tue Feb 21 17:46:24 2017 - [info] Tue Feb 21 17:46:23 2017 - [info] Resetting slave 10.99.73.11(10.99.73.11:3306) and starting replication from the new master 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 17:46:23 2017 - [info] Executed CHANGE MASTER. Tue Feb 21 17:46:23 2017 - [info] Slave started. Tue Feb 21 17:46:24 2017 - [info] gtid_wait(0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103) completed on 10.99.73.11(10.99.73.11:3306). Executed 11 events. Tue Feb 21 17:46:24 2017 - [info] End of log messages from 10.99.73.11. Tue Feb 21 17:46:24 2017 - [info] -- Slave on host 10.99.73.11(10.99.73.11:3306) started. Tue Feb 21 17:46:24 2017 - [info] All new slave servers recovered successfully. Tue Feb 21 17:46:24 2017 - [info] Tue Feb 21 17:46:24 2017 - [info] * Phase 5: New master cleanup phase.. Tue Feb 21 17:46:24 2017 - [info] Tue Feb 21 17:46:24 2017 - [info] Resetting slave info on the new master.. Tue Feb 21 17:46:24 2017 - [info] 10.99.73.10: Resetting slave info succeeded. Tue Feb 21 17:46:24 2017 - [info] Master failover to 10.99.73.10(10.99.73.10:3306) completed successfully. Tue Feb 21 17:46:24 2017 - [info] Deleted server1 entry from /etc/masterha/app1.cnf . Tue Feb 21 17:46:24 2017 - [info] ----- Failover Report ----- app1: MySQL Master failover 10.99.73.9(10.99.73.9:3306) to 10.99.73.10(10.99.73.10:3306) succeeded Master 10.99.73.9(10.99.73.9:3306) is down! Check MHA Manager logs at mha:/var/log/masterha/app1/manager.log for details. Started automated(non-interactive) failover. Selected 10.99.73.10(10.99.73.10:3306) as a new master. 10.99.73.10(10.99.73.10:3306): OK: Applying all logs succeeded. 10.99.73.11(10.99.73.11:3306): OK: Slave started, replicating from 10.99.73.10(10.99.73.10:3306) 10.99.73.10(10.99.73.10:3306): Resetting slave info succeeded. Master failover to 10.99.73.10(10.99.73.10:3306) completed successfully. Tue Feb 21 17:46:24 2017 - [info] Sending mail.. |
看到最后如果出现”Master failover to 10.99.73.10(10.99.73.10:3306) completed successfully.”,说明备选master现在已经上位了。并且可以看到两个slave中10.99.73.10成为了new master,而10.99.73.11成为了10.99.73.10的slave。这主要是因为我们刻意把10.99.73.11设置为了no_master,就是不参与选举。如果没有设置no_master的话,那么MHA在进行选择时会根据数据最接近于master的slave。
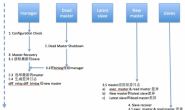
从上面的输出可以看出整个MHA的切换过程,共包括以下的步骤:
1. 配置文件检查阶段,这个阶段会检查整个集群配置文件配置。
2. 宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作(待研究)。
3. 复制dead maste和最新slave相差的relay log,并保存到MHA Manger具体的目录下。
4. 识别含有最新更新的slave。
5. 应用从binlog服务器保存的二进制日志事件(binlog events)。
6. 提升一个slave为新的master进行复制。
7. 使其他的slave连接新的master进行复制。
6)验证new master(10.99.73.10)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (0.31 sec) mysql> show master status; +------------------+----------+--------------+------------------+--------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+--------------------------------------------+ | mysql-bin.000001 | 62292113 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 | +------------------+----------+--------------+------------------+--------------------------------------------+ 1 row in set (0.00 sec) mysql> show slave hosts; +-----------+-------------+------+-----------+--------------------------------------+ | Server_id | Host | Port | Master_id | Slave_UUID | +-----------+-------------+------+-----------+--------------------------------------+ | 103309 | 10.99.73.11 | 3306 | 2000 | c9c57719-edbf-11e6-8f8c-fa163ece854a | +-----------+-------------+------+-----------+--------------------------------------+ 1 row in set (0.00 sec) |
由此结果可以看出new master跟old master的数据一致,说明mha是根据old master来补齐new master的差异数据的。
7)切换发送邮件
最后补充一下邮件发送脚本send_report ,这个脚本在询问一位朋友后可以使用,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 |
#!/usr/bin/perl # Copyright (C) 2011 DeNA Co.,Ltd. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; either version 2 of the License, or # (at your option) any later version. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Mail::Sender; use Getopt::Long; #new_master_host and new_slave_hosts are set only when recovering master succeeded my ( $dead_master_host, $new_master_host, $new_slave_hosts, $subject, $body ); my $smtp='smtp.163.com'; my $mail_from='xxxx'; my $mail_user='xxxxx'; my $mail_pass='xxxxx'; my $mail_to=['xxxx','xxxx']; GetOptions( 'orig_master_host=s' => \$dead_master_host, 'new_master_host=s' => \$new_master_host, 'new_slave_hosts=s' => \$new_slave_hosts, 'subject=s' => \$subject, 'body=s' => \$body, ); mailToContacts($smtp,$mail_from,$mail_user,$mail_pass,$mail_to,$subject,$body); sub mailToContacts { my ( $smtp, $mail_from, $user, $passwd, $mail_to, $subject, $msg ) = @_; open my $DEBUG, "> /tmp/monitormail.log" or die "Can't open the debug file:$!\n"; my $sender = new Mail::Sender { ctype => 'text/plain; charset=utf-8', encoding => 'utf-8', smtp => $smtp, from => $mail_from, auth => 'LOGIN', TLS_allowed => '0', authid => $user, authpwd => $passwd, to => $mail_to, subject => $subject, debug => $DEBUG }; $sender->MailMsg( { msg => $msg, debug => $DEBUG } ) or print $Mail::Sender::Error; return 1; } # Do whatever you want here exit 0; |
切换后报警信息如下:
")
二、手动Failover(MHA Manager必须没有运行)
首先搞一个干净的mysql复制集群加mha监控(在mha监控端不需要开启mha manager)。手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,具体命令如下:
注意:如果,MHA manager检测到没有dead的server,将报错,并结束failover:
|
1 2 3 4 5 6 |
Thu Feb 16 18:18:07 2017 - [info] * Phase 1: Configuration Check Phase.. Thu Feb 16 18:18:07 2017 - [info] Thu Feb 16 18:18:07 2017 - [info] GTID failover mode = 1 Thu Feb 16 18:18:07 2017 - [info] Dead Servers: Thu Feb 16 18:18:07 2017 - [error][/usr/local/share/perl5/MHA/MasterFailover.pm, ln187] None of server is dead. Stop failover. Thu Feb 16 18:18:07 2017 - [error][/usr/local/share/perl5/MHA/ManagerUtil.pm, ln177] Got ERROR: at /usr/local/bin/masterha_master_switch line 53. |
进行手动切换命令如下,但是在切换之前我们需要模拟一下slave延迟,然后让切换脚本自动补全relay log。
在主库(10.99.73.9)上进行sysbench数据生成,在sbtest库下生成sbtest表,共100W记录。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ sysbench /usr/share/sysbench/oltp_read_only.lua \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user=mha \ --mysql-password=123456 \ --mysql-socket=/data/mysql/3306/mysql.sock \ --mysql-db=sbtest \ --db-driver=mysql \ --tables=1 \ --table-size=1000000 \ --report-interval=10 \ --threads=128 \ --time=120 \ prepare |
主库写入一些数据后,就可以关闭10.99.73.10的io_thread。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mysql> stop slave io_thread; Query OK, 0 rows affected (0.08 sec) mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 560000 | +----------+ 1 row in set (0.16 sec) mysql> show master status; +------------------+----------+--------------+------------------+-------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------------------------------+ | mysql-bin.000001 | 34883935 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-59 | +------------------+----------+--------------+------------------+-------------------------------------------+ 1 row in set (0.00 sec) |
然后就可以关闭10.99.73.9的io_thread,但是要保证10.99.73.9主机的数据比10.99.73.10数据多,但是比10.99.73.9的数据小。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mysql> stop slave io_thread; Query OK, 0 rows affected (0.08 sec) mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 660000 | +----------+ 1 row in set (0.16 sec) mysql> show master status; +------------------+----------+--------------+------------------+-------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+-------------------------------------------+ | mysql-bin.000001 | 34889935 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-70 | +------------------+----------+--------------+------------------+-------------------------------------------+ 1 row in set (0.00 sec) |
然后等主库压测完事之后查看一下主库状态就关闭mysql进程。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
$ mysql -S /data/mysql/3306/mysql.sock mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (0.23 sec) mysql> show master status; +------------------+----------+--------------+------------------+--------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+--------------------------------------------+ | mysql-bin.000001 | 62292063 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 | +------------------+----------+--------------+------------------+--------------------------------------------+ 1 row in set (0.00 sec) |
|
1 |
$ mysqladmin -S /data/mysql/3306/mysql.sock shutdown |
然后就可以在mha主机上进行手动切换了,由于要指定特定的slave为候选master,而此slave还落后非常多,可以在每组服务器上都加上check_repl_delay=0表示忽略复制延迟,不然整个恢复过程会加长。如下配置:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
....... [server1] candidate_master=1 hostname=10.99.73.9 port=3306 check_repl_delay=0 [server2] candidate_master=1 hostname=10.99.73.10 port=3306 check_repl_delay=0 [server3] hostname=10.99.73.11 no_master=1 port=3306 check_repl_delay=0 |
手动切换:
|
1 |
$ masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=10.99.73.9 --dead_master_port=3306 --interactive=1 --new_master_host=10.99.73.10 |
会输出整个切换过程以及会询问你是否进行切换,成功后信息如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 |
--dead_master_ip=<dead_master_ip> is not set. Using 10.99.73.9. Tue Feb 21 20:14:56 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Feb 21 20:14:56 2017 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Tue Feb 21 20:14:56 2017 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Tue Feb 21 20:14:56 2017 - [info] MHA::MasterFailover version 0.57. Tue Feb 21 20:14:56 2017 - [info] Starting master failover. Tue Feb 21 20:14:56 2017 - [info] Tue Feb 21 20:14:56 2017 - [info] * Phase 1: Configuration Check Phase.. Tue Feb 21 20:14:56 2017 - [info] Tue Feb 21 20:14:56 2017 - [info] HealthCheck: SSH to 10.99.73.9 is reachable. Tue Feb 21 20:14:56 2017 - [info] Binlog server 10.99.73.9 is reachable. Tue Feb 21 20:14:56 2017 - [info] GTID failover mode = 1 Tue Feb 21 20:14:56 2017 - [info] Dead Servers: Tue Feb 21 20:14:56 2017 - [info] 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:14:56 2017 - [info] Checking master reachability via MySQL(double check)... Tue Feb 21 20:14:56 2017 - [info] ok. Tue Feb 21 20:14:56 2017 - [info] Alive Servers: Tue Feb 21 20:14:56 2017 - [info] 10.99.73.10(10.99.73.10:3306) Tue Feb 21 20:14:56 2017 - [info] 10.99.73.11(10.99.73.11:3306) Tue Feb 21 20:14:56 2017 - [info] Alive Slaves: Tue Feb 21 20:14:56 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 20:14:56 2017 - [info] GTID ON Tue Feb 21 20:14:56 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:14:56 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 20:14:56 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 20:14:56 2017 - [info] GTID ON Tue Feb 21 20:14:56 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:14:56 2017 - [info] Not candidate for the new Master (no_master is set) Master 10.99.73.9(10.99.73.9:3306) is dead. Proceed? (yes/NO): yes Tue Feb 21 20:14:57 2017 - [info] Starting GTID based failover. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] ** Phase 1: Configuration Check Phase completed. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] * Phase 2: Dead Master Shutdown Phase.. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] HealthCheck: SSH to 10.99.73.9 is reachable. Tue Feb 21 20:14:57 2017 - [info] Forcing shutdown so that applications never connect to the current master.. Tue Feb 21 20:14:57 2017 - [warning] master_ip_failover_script is not set. Skipping invalidating dead master IP address. Tue Feb 21 20:14:57 2017 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master. Tue Feb 21 20:14:57 2017 - [info] * Phase 2: Dead Master Shutdown Phase completed. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] * Phase 3: Master Recovery Phase.. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] * Phase 3.1: Getting Latest Slaves Phase.. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] The latest binary log file/position on all slaves is mysql-bin.000001:123299163 Tue Feb 21 20:14:57 2017 - [info] Retrieved Gtid Set: 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 Tue Feb 21 20:14:57 2017 - [info] Latest slaves (Slaves that received relay log files to the latest): Tue Feb 21 20:14:57 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 20:14:57 2017 - [info] GTID ON Tue Feb 21 20:14:57 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:14:57 2017 - [info] Not candidate for the new Master (no_master is set) Tue Feb 21 20:14:57 2017 - [info] The oldest binary log file/position on all slaves is mysql-bin.000001:69047911 Tue Feb 21 20:14:57 2017 - [info] Retrieved Gtid Set: 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-59 Tue Feb 21 20:14:57 2017 - [info] Oldest slaves: Tue Feb 21 20:14:57 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 20:14:57 2017 - [info] GTID ON Tue Feb 21 20:14:57 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:14:57 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] * Phase 3.3: Determining New Master Phase.. Tue Feb 21 20:14:57 2017 - [info] Tue Feb 21 20:14:57 2017 - [info] 10.99.73.10 can be new master. Tue Feb 21 20:14:57 2017 - [info] New master is 10.99.73.10(10.99.73.10:3306) Tue Feb 21 20:14:57 2017 - [info] Starting master failover.. Tue Feb 21 20:14:57 2017 - [info] From: 10.99.73.9(10.99.73.9:3306) (current master) +--10.99.73.10(10.99.73.10:3306) +--10.99.73.11(10.99.73.11:3306) To: 10.99.73.10(10.99.73.10:3306) (new master) +--10.99.73.11(10.99.73.11:3306) Starting master switch from 10.99.73.9(10.99.73.9:3306) to 10.99.73.10(10.99.73.10:3306)? (yes/NO): yes Tue Feb 21 20:14:59 2017 - [info] New master decided manually is 10.99.73.10(10.99.73.10:3306) Tue Feb 21 20:14:59 2017 - [info] Tue Feb 21 20:14:59 2017 - [info] * Phase 3.3: New Master Recovery Phase.. Tue Feb 21 20:14:59 2017 - [info] Tue Feb 21 20:14:59 2017 - [info] Waiting all logs to be applied.. Tue Feb 21 20:14:59 2017 - [info] done. Tue Feb 21 20:14:59 2017 - [info] Replicating from the latest slave 10.99.73.11(10.99.73.11:3306) and waiting to apply.. Tue Feb 21 20:14:59 2017 - [info] Waiting all logs to be applied on the latest slave.. Tue Feb 21 20:14:59 2017 - [info] Resetting slave 10.99.73.10(10.99.73.10:3306) and starting replication from the new master 10.99.73.11(10.99.73.11:3306).. Tue Feb 21 20:14:59 2017 - [info] Executed CHANGE MASTER. Tue Feb 21 20:15:00 2017 - [info] Slave started. Tue Feb 21 20:15:00 2017 - [info] Waiting to execute all relay logs on 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 20:15:03 2017 - [info] master_pos_wait(mysql-bin.000001:62292063) completed on 10.99.73.10(10.99.73.10:3306). Executed 34 events. Tue Feb 21 20:15:03 2017 - [info] done. Tue Feb 21 20:15:03 2017 - [info] done. Tue Feb 21 20:15:03 2017 - [info] -- Saving binlog from host 10.99.73.9 started, pid: 6379 Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] Log messages from 10.99.73.9 ... Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] Fetching binary logs from binlog server 10.99.73.9.. Tue Feb 21 20:15:03 2017 - [info] Executing binlog save command: save_binary_logs --command=save --start_file=mysql-bin.000001 --start_pos=123299163 --output_file=/data/mysql/mha/saved_binlog_binlog1_20170221201456.binlog --handle_raw_binlog=0 --skip_filter=1 --disable_log_bin=0 --manager_version=0.57 --oldest_version=5.7.17-log --binlog_dir=/data/mysql/3306/log/binlog Creating /data/mysql/mha if not exists.. ok. Concat binary/relay logs from mysql-bin.000001 pos 123299163 to mysql-bin.000001 EOF into /data/mysql/mha/saved_binlog_binlog1_20170221201456.binlog .. Concat succeeded. Tue Feb 21 20:15:03 2017 - [info] scp from root@10.99.73.9:/data/mysql/mha/saved_binlog_binlog1_20170221201456.binlog to local:/var/log/masterha/app1/saved_binlog_10.99.73.9_binlog1_20170221201456.binlog succeeded. Tue Feb 21 20:15:03 2017 - [info] End of log messages from 10.99.73.9. Tue Feb 21 20:15:03 2017 - [info] Saved mysqlbinlog size from 10.99.73.9 is 817 bytes. Tue Feb 21 20:15:03 2017 - [info] Applying differential binlog /var/log/masterha/app1/saved_binlog_10.99.73.9_binlog1_20170221201456.binlog .. Tue Feb 21 20:15:03 2017 - [info] Differential log apply from binlog server succeeded. Tue Feb 21 20:15:03 2017 - [info] Getting new master's binlog name and position.. Tue Feb 21 20:15:03 2017 - [info] mysql-bin.000001:62292063 Tue Feb 21 20:15:03 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.99.73.10', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='mysql_slave', MASTER_PASSWORD='xxx'; Tue Feb 21 20:15:03 2017 - [info] Master Recovery succeeded. File:Pos:Exec_Gtid_Set: mysql-bin.000001, 62292063, 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 Tue Feb 21 20:15:03 2017 - [warning] master_ip_failover_script is not set. Skipping taking over new master IP address. Tue Feb 21 20:15:03 2017 - [info] ** Finished master recovery successfully. Tue Feb 21 20:15:03 2017 - [info] * Phase 3: Master Recovery Phase completed. Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] * Phase 4: Slaves Recovery Phase.. Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] * Phase 4.1: Starting Slaves in parallel.. Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] -- Slave recovery on host 10.99.73.11(10.99.73.11:3306) started, pid: 6392. Check tmp log /var/log/masterha/app1/10.99.73.11_3306_20170221201456.log if it takes time.. Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] Log messages from 10.99.73.11 ... Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] Resetting slave 10.99.73.11(10.99.73.11:3306) and starting replication from the new master 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 20:15:03 2017 - [info] Executed CHANGE MASTER. Tue Feb 21 20:15:03 2017 - [info] Slave started. Tue Feb 21 20:15:03 2017 - [info] gtid_wait(0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103) completed on 10.99.73.11(10.99.73.11:3306). Executed 0 events. Tue Feb 21 20:15:03 2017 - [info] End of log messages from 10.99.73.11. Tue Feb 21 20:15:03 2017 - [info] -- Slave on host 10.99.73.11(10.99.73.11:3306) started. Tue Feb 21 20:15:03 2017 - [info] All new slave servers recovered successfully. Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] * Phase 5: New master cleanup phase.. Tue Feb 21 20:15:03 2017 - [info] Tue Feb 21 20:15:03 2017 - [info] Resetting slave info on the new master.. Tue Feb 21 20:15:03 2017 - [info] 10.99.73.10: Resetting slave info succeeded. Tue Feb 21 20:15:03 2017 - [info] Master failover to 10.99.73.10(10.99.73.10:3306) completed successfully. Tue Feb 21 20:15:03 2017 - [info] ----- Failover Report ----- app1: MySQL Master failover 10.99.73.9(10.99.73.9:3306) to 10.99.73.10(10.99.73.10:3306) succeeded Master 10.99.73.9(10.99.73.9:3306) is down! Check MHA Manager logs at mha for details. Started manual(interactive) failover. Selected 10.99.73.10(10.99.73.10:3306) as a new master. 10.99.73.10(10.99.73.10:3306): OK: Applying all logs succeeded. 10.99.73.11(10.99.73.11:3306): OK: Slave started, replicating from 10.99.73.10(10.99.73.10:3306) 10.99.73.10(10.99.73.10:3306): Resetting slave info succeeded. Master failover to 10.99.73.10(10.99.73.10:3306) completed successfully. Tue Feb 21 20:15:03 2017 - [info] Sending mail.. |
上述模拟了master宕机的情况下手动把10.99.73.10提升为主库的操作过程。
查看一下10.99.73.10主机状态。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (0.30 sec) mysql> show master status; +------------------+----------+--------------+------------------+--------------------------------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +------------------+----------+--------------+------------------+--------------------------------------------+ | mysql-bin.000001 | 62292063 | | | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0:1-103 | +------------------+----------+--------------+------------------+--------------------------------------------+ 1 row in set (0.00 sec) mysql> show slave hosts; +-----------+-------------+------+-----------+--------------------------------------+ | Server_id | Host | Port | Master_id | Slave_UUID | +-----------+-------------+------+-----------+--------------------------------------+ | 103309 | 10.99.73.11 | 3306 | 2000 | c9c57719-edbf-11e6-8f8c-fa163ece854a | +-----------+-------------+------+-----------+--------------------------------------+ 1 row in set (0.00 sec) |
可以看到10.99.73.10切换为主后,自动补全了old master所有的差异日志。
masterha_master_switch命令参数介绍
–master_state=dead
这个value可能的取值是:‘dead’or‘alive’。如果设置为alive,就是在线master切换了,这样的场景,master必须是活着的。
–dead_master_host=(hostname)
Dead master的主机信息,包括–dead_master_ip,–dead_master_port。
–new_master_host=(hostname)
New master的主机信息,这个参数是可选项,如果你想特意指定某台机器作为new master,就设置这个参数。如果new_master_host没有设置,那么选举master的规则参考automated master failover( candidate_master parameter )。
–interactive=(0|1)
交互式failover,设置为1(默认)。非交互式failover,设置为0。
–skip_change_master(0.56)
只会完成日志补偿,不会进行change master和start slave。如果你想double check slave是否成功的恢复完成,那么设置该参数对你特别有用。
–skip_disable_read_only
如果设置了这个参数,那么新master将还会是只读状态。如果你想手动开启新master的写权限,那么这个参数特别有用。
–last_failover_minute=(minutes)
同masterha_manager里面的参数一样 。
–ignore_last_failover
同masterha_manager里面的参数一样 。
–wait_on_failover_error=(seconds)
同masterha_manager里面的参数一样。这个参数,只对自动或者非交互式的failover有用,如果–interactive=0没有设置,那么这个参数将不起作用。
–remove_dead_master_conf
同masterha_manager里面的参数一样。
–wait_until_gtid_in_sync=(0|1)
这是基于GTID的参数,如果设置为1(默认): MHA会等待,直到所有slave追上新master的gtid。如果设置为0: 那么MHA不会等待slave追上新master。
–ignore_binlog_server_error
MHA忽略任何binlog server的错误。
三、在线进行切换
在许多情况下,需要将现有的主服务器迁移到另外一台服务器上。比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1)检测复制设置和确定当前主服务器。
2)确定新的主服务器。
3)阻塞写入到当前主服务器。
4)等待所有从服务器赶上复制。
5)授予写入到新的主服务器。
6)重新设置从服务器。
注意,在线切换的时候应用架构需要考虑以下两个问题:
1)自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2)负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1)所有slave的IO线程都在运行。
2)所有slave的SQL线程都在运行。
3)所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4)在master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
在线切换步骤如下:
首先,停掉MHA监控:
|
1 |
[root@mha ~]# masterha_stop --conf=/etc/masterha/app1.cnf |
注意:由于在线进行切换需要调用到master_ip_online_change这个脚本,但是由于该脚本不完整,需要自己进行相应的修改,我google到后发现还是有问题,脚本中new_master_password这个变量获取不到,导致在线切换失败,所以进行了相关的硬编码,直接把mysql的mha用户密码赋值给变量new_master_password,如果有哪位大牛知道原因,请指点指点。这个脚本还可以管理vip。下面贴出脚本:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 |
#!/usr/bin/env perl # Copyright (C) 2011 DeNA Co.,Ltd. # # This program is free software; you can redistribute it and/or modify # it under the terms of the GNU General Public License as published by # the Free Software Foundation; either version 2 of the License, or # (at your option) any later version. # # This program is distributed in the hope that it will be useful, # but WITHOUT ANY WARRANTY; without even the implied warranty of # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the # GNU General Public License for more details. # # You should have received a copy of the GNU General Public License # along with this program; if not, write to the Free Software # Foundation, Inc., # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA ## Note: This is a sample script and is not complete. Modify the script based on your environment. use strict; use warnings FATAL => 'all'; use Getopt::Long; use MHA::DBHelper; use MHA::NodeUtil; use Time::HiRes qw( sleep gettimeofday tv_interval ); use Data::Dumper; my $_tstart; my $_running_interval = 0.1; my ( $command, $orig_master_host, $orig_master_ip, $orig_master_port, $orig_master_user, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, ); my $vip = '10.99.73.100/24'; # Virtual IP my $key = "1"; my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip"; my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down"; my $ssh_user = "root"; my $new_master_password='123456'; my $orig_master_password='123456'; GetOptions( 'command=s' => \$command, #'ssh_user=s' => \$ssh_user, 'orig_master_host=s' => \$orig_master_host, 'orig_master_ip=s' => \$orig_master_ip, 'orig_master_port=i' => \$orig_master_port, 'orig_master_user=s' => \$orig_master_user, #'orig_master_password=s' => \$orig_master_password, 'new_master_host=s' => \$new_master_host, 'new_master_ip=s' => \$new_master_ip, 'new_master_port=i' => \$new_master_port, 'new_master_user=s' => \$new_master_user, #'new_master_password=s' => \$new_master_password, ); exit &main(); sub current_time_us { my ( $sec, $microsec ) = gettimeofday(); my $curdate = localtime($sec); return $curdate . " " . sprintf( "%06d", $microsec ); } sub sleep_until { my $elapsed = tv_interval($_tstart); if ( $_running_interval > $elapsed ) { sleep( $_running_interval - $elapsed ); } } sub get_threads_util { my $dbh = shift; my $my_connection_id = shift; my $running_time_threshold = shift; my $type = shift; $running_time_threshold = 0 unless ($running_time_threshold); $type = 0 unless ($type); my @threads; my $sth = $dbh->prepare("SHOW PROCESSLIST"); $sth->execute(); while ( my $ref = $sth->fetchrow_hashref() ) { my $id = $ref->{Id}; my $user = $ref->{User}; my $host = $ref->{Host}; my $command = $ref->{Command}; my $state = $ref->{State}; my $query_time = $ref->{Time}; my $info = $ref->{Info}; $info =~ s/^\s*(.*?)\s*$/$1/ if defined($info); next if ( $my_connection_id == $id ); next if ( defined($query_time) && $query_time < $running_time_threshold ); next if ( defined($command) && $command eq "Binlog Dump" ); next if ( defined($user) && $user eq "system user" ); next if ( defined($command) && $command eq "Sleep" && defined($query_time) && $query_time >= 1 ); if ( $type >= 1 ) { next if ( defined($command) && $command eq "Sleep" ); next if ( defined($command) && $command eq "Connect" ); } if ( $type >= 2 ) { next if ( defined($info) && $info =~ m/^select/i ); next if ( defined($info) && $info =~ m/^show/i ); } push @threads, $ref; } return @threads; } sub main { if ( $command eq "stop" ) { ## Gracefully killing connections on the current master # 1. Set read_only= 1 on the new master # 2. DROP USER so that no app user can establish new connections # 3. Set read_only= 1 on the current master # 4. Kill current queries # * Any database access failure will result in script die. my $exit_code = 1; eval { ## Setting read_only=1 on the new master (to avoid accident) my $new_master_handler = new MHA::DBHelper(); # args: hostname, port, user, password, raise_error(die_on_error)_or_not $new_master_handler->connect( $new_master_ip, $new_master_port, $new_master_user, $new_master_password, 1 ); print current_time_us() . " Set read_only on the new master.. "; $new_master_handler->enable_read_only(); if ( $new_master_handler->is_read_only() ) { print "ok.\n"; } else { die "Failed!\n"; } $new_master_handler->disconnect(); # Connecting to the orig master, die if any database error happens my $orig_master_handler = new MHA::DBHelper(); $orig_master_handler->connect( $orig_master_ip, $orig_master_port, $orig_master_user, $orig_master_password, 1 ); ## Drop application user so that nobody can connect. Disabling per-session binlog beforehand #$orig_master_handler->disable_log_bin_local(); #print current_time_us() . " Drpping app user on the orig master..\n"; #FIXME_xxx_drop_app_user($orig_master_handler); ## Waiting for N * 100 milliseconds so that current connections can exit my $time_until_read_only = 15; $_tstart = [gettimeofday]; my @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); while ( $time_until_read_only > 0 && $#threads >= 0 ) { if ( $time_until_read_only % 5 == 0 ) { printf "%s Waiting all running %d threads are disconnected.. (max %d milliseconds)\n", current_time_us(), $#threads + 1, $time_until_read_only * 100; if ( $#threads < 5 ) { print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n" foreach (@threads); } } sleep_until(); $_tstart = [gettimeofday]; $time_until_read_only--; @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); } ## Setting read_only=1 on the current master so that nobody(except SUPER) can write print current_time_us() . " Set read_only=1 on the orig master.. "; $orig_master_handler->enable_read_only(); if ( $orig_master_handler->is_read_only() ) { print "ok.\n"; } else { die "Failed!\n"; } ## Waiting for M * 100 milliseconds so that current update queries can complete my $time_until_kill_threads = 5; @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); while ( $time_until_kill_threads > 0 && $#threads >= 0 ) { if ( $time_until_kill_threads % 5 == 0 ) { printf "%s Waiting all running %d queries are disconnected.. (max %d milliseconds)\n", current_time_us(), $#threads + 1, $time_until_kill_threads * 100; if ( $#threads < 5 ) { print Data::Dumper->new( [$_] )->Indent(0)->Terse(1)->Dump . "\n" foreach (@threads); } } sleep_until(); $_tstart = [gettimeofday]; $time_until_kill_threads--; @threads = get_threads_util( $orig_master_handler->{dbh}, $orig_master_handler->{connection_id} ); } print "Disabling the VIP on old master: $orig_master_host \n"; &stop_vip(); ## Terminating all threads print current_time_us() . " Killing all application threads..\n"; $orig_master_handler->kill_threads(@threads) if ( $#threads >= 0 ); print current_time_us() . " done.\n"; #$orig_master_handler->enable_log_bin_local(); $orig_master_handler->disconnect(); ## After finishing the script, MHA executes FLUSH TABLES WITH READ LOCK $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "start" ) { ## Activating master ip on the new master # 1. Create app user with write privileges # 2. Moving backup script if needed # 3. Register new master's ip to the catalog database # We don't return error even though activating updatable accounts/ip failed so that we don't interrupt slaves' recovery. # If exit code is 0 or 10, MHA does not abort my $exit_code = 10; eval { my $new_master_handler = new MHA::DBHelper(); # args: hostname, port, user, password, raise_error_or_not $new_master_handler->connect( $new_master_ip, $new_master_port, $new_master_user, $new_master_password, 1 ); ## Set read_only=0 on the new master #$new_master_handler->disable_log_bin_local(); print current_time_us() . " Set read_only=0 on the new master.\n"; $new_master_handler->disable_read_only(); ## Creating an app user on the new master #print current_time_us() . " Creating app user on the new master..\n"; #FIXME_xxx_create_app_user($new_master_handler); #$new_master_handler->enable_log_bin_local(); $new_master_handler->disconnect(); ## Update master ip on the catalog database, etc print "Enabling the VIP - $vip on the new master - $new_master_host \n"; &start_vip(); $exit_code = 0; }; if ($@) { warn "Got Error: $@\n"; exit $exit_code; } exit $exit_code; } elsif ( $command eq "status" ) { # do nothing exit 0; } else { &usage(); exit 1; } } # A simple system call that enable the VIP on the new master sub start_vip() { `ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`; } # A simple system call that disable the VIP on the old_master sub stop_vip() { `ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`; } sub usage { print "Usage: master_ip_online_change --command=start|stop|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n"; die; } |
然后可以在主库(10.99.73.9)上进行sysbench数据生成,在sbtest库下生成sbtest表,共100W记录。
|
1 |
mysql> create database sbtest charset utf8mb4; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
$ sysbench /usr/share/sysbench/oltp_read_only.lua \ --mysql-host=127.0.0.1 \ --mysql-port=3306 \ --mysql-user=mha \ --mysql-password=123456 \ --mysql-socket=/data/mysql/3306/mysql.sock \ --mysql-db=sbtest \ --db-driver=mysql \ --tables=1 \ --table-size=1000000 \ --report-interval=10 \ --threads=128 \ --time=120 \ prepare |
有条件的可以在压测时连接数据指定VIP地址,把socket去掉,添加–mysql-host=10.99.73.100,这就样可以模拟应用在线切换(一边压测一边切换)。
等主库一压测完后。就可以进行在线切换操作(模拟在线切换主库操作,原主库10.99.73.9变为slave,10.99.73.10提升为新的主库)。
|
1 |
[root@mha ~]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=10.99.73.10 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000 |
其中参数的意思:
–orig_master_is_new_slave
切换时加上此参数是将原master变为slave节点,如果不加此参数,原来的master将不启动。
–running_updates_limit=10000
故障切换时,候选master如果有延迟的话, mha切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover时relay日志的大小决定。
最后查看日志,了解切换过程,最后输出信息如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
Tue Feb 21 20:27:34 2017 - [info] MHA::MasterRotate version 0.57. Tue Feb 21 20:27:34 2017 - [info] Starting online master switch.. Tue Feb 21 20:27:34 2017 - [info] Tue Feb 21 20:27:34 2017 - [info] * Phase 1: Configuration Check Phase.. Tue Feb 21 20:27:34 2017 - [info] Tue Feb 21 20:27:34 2017 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Feb 21 20:27:34 2017 - [info] Reading application default configuration from /etc/masterha/app1.cnf.. Tue Feb 21 20:27:34 2017 - [info] Reading server configuration from /etc/masterha/app1.cnf.. Tue Feb 21 20:27:34 2017 - [info] GTID failover mode = 1 Tue Feb 21 20:27:34 2017 - [info] Current Alive Master: 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:27:34 2017 - [info] Alive Slaves: Tue Feb 21 20:27:34 2017 - [info] 10.99.73.10(10.99.73.10:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 20:27:34 2017 - [info] GTID ON Tue Feb 21 20:27:34 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:27:34 2017 - [info] Primary candidate for the new Master (candidate_master is set) Tue Feb 21 20:27:34 2017 - [info] 10.99.73.11(10.99.73.11:3306) Version=5.7.17-log (oldest major version between slaves) log-bin:enabled Tue Feb 21 20:27:34 2017 - [info] GTID ON Tue Feb 21 20:27:34 2017 - [info] Replicating from 10.99.73.9(10.99.73.9:3306) Tue Feb 21 20:27:34 2017 - [info] Not candidate for the new Master (no_master is set) It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 10.99.73.9(10.99.73.9:3306)? (YES/no): yes Tue Feb 21 20:27:37 2017 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time.. Tue Feb 21 20:27:37 2017 - [info] ok. Tue Feb 21 20:27:37 2017 - [info] Checking MHA is not monitoring or doing failover.. Tue Feb 21 20:27:37 2017 - [info] Checking replication health on 10.99.73.10.. Tue Feb 21 20:27:37 2017 - [info] ok. Tue Feb 21 20:27:37 2017 - [info] Checking replication health on 10.99.73.11.. Tue Feb 21 20:27:37 2017 - [info] ok. Tue Feb 21 20:27:37 2017 - [info] 10.99.73.10 can be new master. Tue Feb 21 20:27:37 2017 - [info] From: 10.99.73.9(10.99.73.9:3306) (current master) +--10.99.73.10(10.99.73.10:3306) +--10.99.73.11(10.99.73.11:3306) To: 10.99.73.10(10.99.73.10:3306) (new master) +--10.99.73.11(10.99.73.11:3306) +--10.99.73.9(10.99.73.9:3306) Starting master switch from 10.99.73.9(10.99.73.9:3306) to 10.99.73.10(10.99.73.10:3306)? (yes/NO): yes Tue Feb 21 20:27:38 2017 - [info] Checking whether 10.99.73.10(10.99.73.10:3306) is ok for the new master.. Tue Feb 21 20:27:38 2017 - [info] ok. Tue Feb 21 20:27:38 2017 - [info] 10.99.73.9(10.99.73.9:3306): SHOW SLAVE STATUS returned empty result. To check replication filtering rules, temporarily executing CHANGE MASTER to a dummy host. Tue Feb 21 20:27:38 2017 - [info] 10.99.73.9(10.99.73.9:3306): Resetting slave pointing to the dummy host. Tue Feb 21 20:27:38 2017 - [info] ** Phase 1: Configuration Check Phase completed. Tue Feb 21 20:27:38 2017 - [info] Tue Feb 21 20:27:38 2017 - [info] * Phase 2: Rejecting updates Phase.. Tue Feb 21 20:27:38 2017 - [info] Tue Feb 21 20:27:38 2017 - [info] Executing master ip online change script to disable write on the current master: Tue Feb 21 20:27:38 2017 - [info] /usr/local/bin/master_ip_online_change --command=stop --orig_master_host=10.99.73.9 --orig_master_ip=10.99.73.9 --orig_master_port=3306 --orig_master_user='mha' --orig_master_password='123456' --new_master_host=10.99.73.10 --new_master_ip=10.99.73.10 --new_master_port=3306 --new_master_user='mha' --new_master_password='123456' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave Unknown option: orig_master_password Unknown option: new_master_password Unknown option: orig_master_ssh_user Unknown option: new_master_ssh_user Unknown option: orig_master_is_new_slave Tue Feb 21 20:27:38 2017 979086 Set read_only on the new master.. ok. Disabling the VIP on old master: 10.99.73.9 Tue Feb 21 20:27:41 2017 110472 Killing all application threads.. Tue Feb 21 20:27:41 2017 111520 done. Tue Feb 21 20:27:41 2017 - [info] ok. Tue Feb 21 20:27:41 2017 - [info] Locking all tables on the orig master to reject updates from everybody (including root): Tue Feb 21 20:27:41 2017 - [info] Executing FLUSH TABLES WITH READ LOCK.. Tue Feb 21 20:27:41 2017 - [info] ok. Tue Feb 21 20:27:41 2017 - [info] Orig master binlog:pos is mysql-bin.000002:123299366. Tue Feb 21 20:27:41 2017 - [info] Waiting to execute all relay logs on 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 20:27:41 2017 - [info] master_pos_wait(mysql-bin.000002:123299366) completed on 10.99.73.10(10.99.73.10:3306). Executed 0 events. Tue Feb 21 20:27:41 2017 - [info] done. Tue Feb 21 20:27:41 2017 - [info] Getting new master's binlog name and position.. Tue Feb 21 20:27:41 2017 - [info] mysql-bin.000001:124584135 Tue Feb 21 20:27:41 2017 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='10.99.73.10', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='mysql_slave', MASTER_PASSWORD='xxx'; Tue Feb 21 20:27:41 2017 - [info] Executing master ip online change script to allow write on the new master: Tue Feb 21 20:27:41 2017 - [info] /usr/local/bin/master_ip_online_change --command=start --orig_master_host=10.99.73.9 --orig_master_ip=10.99.73.9 --orig_master_port=3306 --orig_master_user='mha' --orig_master_password='123456' --new_master_host=10.99.73.10 --new_master_ip=10.99.73.10 --new_master_port=3306 --new_master_user='mha' --new_master_password='123456' --orig_master_ssh_user=root --new_master_ssh_user=root --orig_master_is_new_slave Unknown option: orig_master_password Unknown option: new_master_password Unknown option: orig_master_ssh_user Unknown option: new_master_ssh_user Unknown option: orig_master_is_new_slave Tue Feb 21 20:27:41 2017 228582 Set read_only=0 on the new master. Enabling the VIP - 10.99.73.100/24 on the new master - 10.99.73.10 Tue Feb 21 20:27:41 2017 - [info] ok. Tue Feb 21 20:27:41 2017 - [info] Tue Feb 21 20:27:41 2017 - [info] * Switching slaves in parallel.. Tue Feb 21 20:27:41 2017 - [info] Tue Feb 21 20:27:41 2017 - [info] -- Slave switch on host 10.99.73.11(10.99.73.11:3306) started, pid: 6612 Tue Feb 21 20:27:41 2017 - [info] Tue Feb 21 20:27:41 2017 - [info] Log messages from 10.99.73.11 ... Tue Feb 21 20:27:41 2017 - [info] Tue Feb 21 20:27:41 2017 - [info] Waiting to execute all relay logs on 10.99.73.11(10.99.73.11:3306).. Tue Feb 21 20:27:41 2017 - [info] master_pos_wait(mysql-bin.000002:123299366) completed on 10.99.73.11(10.99.73.11:3306). Executed 0 events. Tue Feb 21 20:27:41 2017 - [info] done. Tue Feb 21 20:27:41 2017 - [info] Resetting slave 10.99.73.11(10.99.73.11:3306) and starting replication from the new master 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 20:27:41 2017 - [info] Executed CHANGE MASTER. Tue Feb 21 20:27:41 2017 - [info] Slave started. Tue Feb 21 20:27:41 2017 - [info] End of log messages from 10.99.73.11 ... Tue Feb 21 20:27:41 2017 - [info] Tue Feb 21 20:27:41 2017 - [info] -- Slave switch on host 10.99.73.11(10.99.73.11:3306) succeeded. Tue Feb 21 20:27:41 2017 - [info] Unlocking all tables on the orig master: Tue Feb 21 20:27:41 2017 - [info] Executing UNLOCK TABLES.. Tue Feb 21 20:27:41 2017 - [info] ok. Tue Feb 21 20:27:41 2017 - [info] Starting orig master as a new slave.. Tue Feb 21 20:27:41 2017 - [info] Resetting slave 10.99.73.9(10.99.73.9:3306) and starting replication from the new master 10.99.73.10(10.99.73.10:3306).. Tue Feb 21 20:27:41 2017 - [info] Executed CHANGE MASTER. Tue Feb 21 20:27:42 2017 - [info] Slave started. Tue Feb 21 20:27:42 2017 - [info] All new slave servers switched successfully. Tue Feb 21 20:27:42 2017 - [info] Tue Feb 21 20:27:42 2017 - [info] * Phase 5: New master cleanup phase.. Tue Feb 21 20:27:42 2017 - [info] Tue Feb 21 20:27:42 2017 - [info] 10.99.73.10: Resetting slave info succeeded. Tue Feb 21 20:27:42 2017 - [info] Switching master to 10.99.73.10(10.99.73.10:3306) completed successfully. |
查看10.99.73.10主机切换为master了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
mysql> show slave hosts; +-----------+-------------+------+-----------+--------------------------------------+ | Server_id | Host | Port | Master_id | Slave_UUID | +-----------+-------------+------+-----------+--------------------------------------+ | 103309 | 10.99.73.11 | 3306 | 2000 | c9c57719-edbf-11e6-8f8c-fa163ece854a | | 10 | | 3306 | 2000 | 0f7c2151-edc0-11e6-ab9e-fa163e2ebbf0 | +-----------+-------------+------+-----------+--------------------------------------+ 2 rows in set (0.00 sec) mysql> select count(*) from sbtest.sbtest; +----------+ | count(*) | +----------+ | 1000000 | +----------+ 1 row in set (0.20 sec) |
PS:online切换主从状态必须正常,切换后old maser会变成slave,且为read_only模式。
四、修复宕机的Master
通常情况下自动切换以后,原master可能已经废弃掉,待原master主机修复后,如果数据完整的情况下,可能想把原来master重新作为新主库的slave,这时我们可以借助当时自动切换时刻的MHA日志来完成对原master的修复。下面是提取相关日志的命令:
|
1 2 3 |
[root@192.168.0.20 app1]# grep -i "All other slaves should start" manager.log Mon Apr 21 22:28:33 2014 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.0.60', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000022', MASTER_LOG_POS=506716, MASTER_USER='repl', MASTER_PASSWORD='xxx'; |
获取上述信息以后,就可以直接在修复后的master上执行change master to相关操作,重新作为从库了。