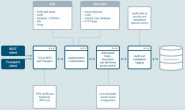
ELK Stack平台搭建

1)Redis:接收用户日志的消息队列。
2)Logstash:做日志解析,统一成JSON输出给Elasticsearch。
3)Elasticsearch:实时日志分析服务的核心技术,一个schemaless,实时的数据存储服务,通过index组织数据,兼具强大的搜索和统计功能。
4)Kibana:基于Elasticsearch的数据可视化组件,超强的数据可视化能力是众多公司选择ELK stack的重要原因。
我们一步步安装部署ELK Stack系统的各个组件,然后以网站访问日志为例进行数据实时分析。
首先,到ELK 官网下载需要用到的Filebeat/Logstash/Elasticsearch/Kibana软件安装包。(推荐下载编译好的二进制可执行文件,直接解压执行就可以部署)
1. 系统环境
|
1 2 3 4 5 6 7 |
System: Centos release 7.2 (Final) ElasticSearch: 2.3.2 Logstash: 2.3.2 Kibana: 4.5.0 Java: openjdk version "1.8.0_131" redis: 3.2.0 Nginx: 1.6.2 |
2. 软件下载
|
1 2 3 4 |
wget https://download.elastic.co/logstash/logstash/logstash-2.3.2.tar.gz wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/tar/elasticsearch/2.3.2/elasticsearch-2.3.2.tar.gz wget https://download.elastic.co/kibana/kibana/kibana-4.5.0-linux-x64.tar.gz wget https://github.com/antirez/redis/archive/3.2.0.tar.gz |
这里我下载是我所使用的软件版本(都是当前最新版),如果你想使用旧一点或者更新一点的版本可以自行下载。
|
1 2 3 4 5 |
$ ll -rw-r--r--. 1 root root 27543334 4月 26 18:58 elasticsearch-2.3.2.tar.gz -rw-r--r--. 1 root root 32617245 3月 29 06:46 kibana-4.5.0-linux-x64.tar.gz -rw-r--r--. 1 root root 74898843 4月 26 22:48 logstash-2.3.2.tar.gz -rw-r--r--. 1 root root 1539364 5月 8 07:47 3.2.0.tar.gz |
3. 安装部署Nginx
这里我们部署ELK之前,需要一个产生日志的源,这里呢就选项Nginx服务器。
默认情况下,CentOS的官方资源是没有php-fpm和Nginx的,需要安装第三方资源库即可。(此步骤可省略)
|
1 2 3 |
$ wget http://www.atomicorp.com/installers/atomic $ sh ./atomic $ yum check-update |
安装启动nginx(关于nginx可以看本博客也有详细介绍)
|
1 2 |
$ yum install nginx -y $ nginx |
|
1 2 |
$ netstat -nplt | grep nginx tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 12719/nginx: master |
nginx的访问日志格式定义,默认如下:
|
1 2 |
log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' |
在/etc/nginx/conf.d/default.conf中添加如下一行,定义nginx日志使用的格式,以及日志文件的位置。
|
1 |
access_log /var/log/nginx/access.log main; |
然后重新启动nginx
|
1 2 |
$ nginx -s stop $ nginx |
4. 安装部署Redis
在安装Redis之前,需要安装Redis的依赖程序tcl,如果不安装tcl在Redis执行make test的时候就会报错的哦。
|
1 2 |
$ yum install tcl -y $ yum groupinstall "Development Tools" "Compatibility Libraries" -y |
|
1 2 3 4 5 6 7 8 9 |
$ tar xvf 3.2.0.tar.gz -C /usr/local $ cd /usr/local $ mv redis-3.2.0 redis $ cd redis $ make $ make test $ make install $ mkdir /etc/redis $ cp redis/redis.conf /etc |
配置redis
|
1 2 |
$ cat /etc/redis.conf daemonize yes #把no改为yes设置redis在后台运行; |
启动redis
|
1 |
$ redis-server /etc/redis.conf |
|
1 2 |
$ netstat -ntpl | grep redis tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 12434/redis-server |
5. 安装JAVA
由于Logstash/Elastisearch的运行依赖于Java环境, 而Logstash 1.5以上版本依赖java版本不能低于java 1.7,因此推荐使用最新版本的Java。因为我们只需要Java的运行环境,所以可以只安装JRE,不过这里我依然使用JDK。由于我使用的是CentOS7系统,java版本是1.8,符合需求,我就使用yum直接安装了。
|
1 |
$ yum install java-1.8.0-openjdk |
查看JAVA版本
|
1 2 3 4 |
$ java -version openjdk version "1.8.0_131" OpenJDK Runtime Environment (build 1.8.0_131-b11) OpenJDK 64-Bit Server VM (build 25.131-b11, mixed mode) |
如果java -version没有问题,就不需要设置环境变量。一般使用yum安装的jdk不需要设置JAVA_HOME环境变量。如果你是使用二进制版本安装的jdk,那么可能需要设置一下JAVA_HOME环境变量,具体的JAVA_HOME环境变量设置根据安装路径不同而不同。
6. 安装Logstash
|
1 |
$ tar xvf logstash-2.3.2.tar.gz -C /usr/local/ |
把logstash解压后就可以使用了,是不是很简单。和所有的编程语言一样,我们以一个输出 “hello world” 的形式开始我们的logstash学习。
6.1 开始使用logstash
在终端中,像下面这样运行命令来启动 Logstash 进程:
|
1 2 |
$ /usr/local/logstash-2.3.2/bin/logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' hello world |
执行完命令,然后你会发现终端在等待你的输入。没问题,敲入hello world,然后回车,logstash会返回以下结果!
|
1 2 3 4 5 6 |
{ "message" => "Hehello world", "@version" => "1", "@timestamp" => "2016-05-08T00:36:00.300Z", "host" => "localhost.localdomain" } |
输出没有问题,就证明可以正式来使用logstash了。
解释一下命令含义
每位系统管理员都肯定写过很多类似这样的命令:cat randdata | awk ‘{print $2}’ | sort | uniq -c | tee sortdata。这个管道符|可以算是Linux世界最伟大的发明之一(另一个是“一切皆文件”)。Logstash就像管道符一样!你输入(就像命令行的 cat )数据,然后处理过滤(就像 awk 或者 uniq 之类)数据,最后输出(就像 tee )到其他地方。
Logstash会给事件添加一些额外信息。最重要的就是@timestamp,用来标记事件的发生时间。因为这个字段涉及到Logstash的内部流转,所以必须是一个job对象,如果你尝试自己给一个字符串字段重命名为@timestamp的话,Logstash会直接报错。所以,请使用filters/date插件来管理这个特殊字段。
此外,大多数时候,还可以见到另外几个:
host – 标记事件发生在哪里。
type – 标记事件的唯一类型。
tags – 标记事件的某方面属性,这是一个数组,一个事件可以有多个标签。
你可以随意给事件添加字段或者从事件里删除字段。事实上事件就是一个 Ruby对象,或者更简单的理解为就是一个哈希也行。
小贴士:每个logstash过滤插件,都会有四个方法叫add_tag, remove_tag, add_field和remove_field。它们在插件过滤匹配成功时生效。
Logstash的运行方式为主程序+配置文件。Collect,Enrich和Transport的行为在配置文件中定义。配置文件的格式有点像json。
|
1 2 |
$ nohup /usr/local/logstash-2.3.2/bin/logstash -f /usr/local/logstash-2.3.2/etc/logstash_shipper.conf & $ nohup /usr/local/logstash-2.3.2/bin/logstash -f /usr/local/logstash-2.3.2/etc/logstash_indexer.conf & |
|
1 2 3 |
$ jobs [1]- 运行中 nohup /usr/local/logstash-2.3.2/bin/logstash -f /usr/local/logstash-2.3.2/etc/logstash_shipper.conf & [2]+ 运行中 nohup /usr/local/logstash-2.3.2/bin/logstash -f /usr/local/logstash-2.3.2/etc/logstash_indexer.conf & |
上面只是一个小小的测试,下面就为logstash提供日志推送配置文件。
编写Shipper角色的配置文件:logstash_shipper.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
$ cat /usr/local/logstash-2.3.2/etc/logstash_shipper.conf input { file { type => "nginx_access log" #这里定义的是日志文件名; path => ["/var/log/nginx/access.log"] #这里定义的是日志文件路径; } } output { redis { host => "localhost" #redis主机地址,这里是本机; port => 6379 #redis端口号; data_type => "list" #使用redis队列模式; key => "logstash:redis" #队列通道的名称; } } |
如上,input描述的就是数据如何输入,这里填写你需要收集的本机日志文件路径,我收集的是nginx的日志。output描述的就是数据如何输出。这里描述的是输出到Redis。
输出到Redis中,data_type的可选值有channel和list两种。用过Redis的人知道,channel是Redis的发布/订阅通信模式,而list是Redis的队列数据结构。两者都可以用来实现系统间有序的消息异步通信。channel相比list的好处是,解除了发布者和订阅者之间的耦合。举个例子,一个Indexer在持续读取Redis中的记录,现在想加入第二个Indexer,如果使用list,就会出现上一条记录被第一个Indexer取走,而下一条记录被第二个Indexer取走的情况,两个Indexer之间产生了竞争,导致任何一方都没有读到完整的日志。channel就可以避免这种情况。这里的Shipper和下面将要提到的Indexer配置文件中都使用了channel。
编写Indexer角色的配置文件:logstash_indexer.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
$ cat /usr/local/logstash-2.3.2/etc/logstash_indexer.conf input { redis { #去redis队列取数据; host => "localhost" #连接redis服务器; port => 6379 #连接redis端口; data_type => "list" #数据类型; key => "logstash:redis" #队列名称; } } output { elasticsearch { #Logstash输出到elasticsearch; hosts => ["localhost"] #elasticsearch为本地; index => "logstash-nginx-%{+YYYY.MM.dd}" #创建索引; document_type => "nginx" #文档类型; workers => 1 #进程数量; flush_size => 20000 idle_flush_time => 10 } } |
如上配置文件,input定义了从Redis中读取数据;而output我是输出到了本地的elasticsearch中存储。
Logstash传递的每条数据都带有元数据,如@version,@timestamp,host等等,有些可以修改,有些不允许修改。host记录的是当前的主机信息。Logstash可能不会去获取主机的信息或者获取的不准,这里建议替换成自己定义的主机标示,以保证最终的日志输出可以有完美的格式。
7. 安装使用Elastcearch
|
1 |
$ tar xvf elasticsearch-2.3.2.tar.gz -C /usr/local |
同Logstash一样,解压完就可以使用了。但是注意使用elasticsearch不能使用root用户,所以这里我创建了一个elk用户,把elasticsearch.2.3.2目录及子目录的属主和属组改为elk用户了。
|
1 2 |
$ useradd elk $ chown elk.elk -R /usr/local/elastcsearch.2.3.2 |
启动elasticsearch
|
1 |
$ nohup sudo -u elk /usr/local/elasticsearch-2.3.2/bin/elasticsearch & |
查看启动进程,会发现,elasticsearch除了127.0.0.1地址开启了一个9200端口外,还有一个::1:9200的IPV6地址,也就是说除了本地能访问elasticsearch之外,外面是无法访问的。
|
1 2 3 |
$ netstat -nplt | grep 9200 tcp6 0 0 127.0.0.1:9200 :::* LISTEN 4924/java tcp6 0 0 ::1:9200 :::* LISTEN 4924/java |
修改elasticsearch配置文件,添加如下几行(注意开启network.host):
|
1 2 3 4 5 6 7 8 |
$ cat /usr/local/elasticsearch-2.3.2/config/elasticsearch.yml cluster.name: elasticsearch node.name: node1 node.box_type: stale path.data: ['/data/elasticsearch'] path.logs: /var/log/elasticsearch/ network.host: 0.0.0.0 index.number_of_replicas: 0 |
具体elasticsearch配置文件参数介绍请看:ELK技术实战–Elasticsearch配置文件详解
创建elasticsearch需要的数据目录和日志目录。
|
1 2 3 4 |
$ mkdir -p /data/elasticsearch $ mkdir -p /var/log/elasticsearch/ $ chown elk.elk /data/elasticsearch/ -R $ chown elk.elk /var/log/elasticsearch/ -R |
然后关闭elasticsearch,重新开始后再次查看elasticsearch的监听地址为:::9200了。
|
1 2 |
$ netstat -nplt | grep 9200 tcp6 0 0 :::9200 :::* LISTEN 5026/java |
然后使用curl访问http://localhost:9200/?pretty
|
1 |
$ curl http://localhost:9200/?pretty |
地址或者通过浏览器访问,如果可以看到类似下面的返回,说明启动成功:

注意:如果访问不了,就看看是不是iptables没有关闭,或者监听的地址和端口有问题。另外注意elasticsearch使用的是elk用户,启动时多看日志。
7.1 Elasticsearch安装head插件
Elasticsearch有很多插件,插件能额外扩展elasticsearch功能,提供各类功能等等。有三种类型的插件:
1)java插件
只包含JAR文件,必须在集群中每个节点上安装而且需要重启才能使插件生效。
2)网站插件
这类插件包含静态web内容,如js、css、html等等,可以直接从elasticsearch服务,如head插件。只需在一个节点上安装,不需要重启服务。可以通过下面的URL访问,如:http://node-ip:9200/_plugin/plugin_name
3)混合插件
顾名思义,就是包含上面两种的插件。
这里就说head插件,我们要用它来查看elasticsearch集群状态和索引情况。
安装head插件
|
1 2 3 4 |
$ /usr/local/elasticsearch-2.3.2/bin/plugin install mobz/elasticsearch-head -> Installing mobz/elasticsearch-head... Trying https://github.com/mobz/elasticsearch-head/archive/master.zip ... Downloading ....................... |
查看已安装的插件
|
1 2 3 |
$ /usr/local/elasticsearch-2.3.2/bin/plugin list Installed plugins in /usr/local/elasticsearch-2.3.2/plugins: - head |
基本插件管理命令
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ /usr/local/elasticsearch-2.3.2/bin/plugin -h NAME plugin - Manages plugins SYNOPSIS plugin <command> DESCRIPTION Manage plugins COMMANDS install Install a plugin remove Remove a plugin list List installed plugins NOTES [*] For usage help on specific commands please type "plugin <command> -h" |
访问head插件

Elasticsearch集群状态应该为green,由于我这里elasticsearch只有一个节点,所以配置中副本设置为0,默认为1一个副本:
|
1 |
index.number_of_replicas: 0 |
如果把副本设置为1,但又只有一个elasticsearch节点,那么访问head会出现如下画面,集群状态为yellow,这是由于有一个副本节点没有识别到:

Elasticsearch具体使用方式,后面介绍。
8. 安装kibana
Kibana安装跟logstash、elasticsearch一样不需要安装,解压就能用。
|
1 |
$ tar xvf kibana-4.5.0-linux-x64.tar.gz -C /usr/local/ |
启动Kibana
|
1 |
$ nohup /usr/local/kibana-4.5.0-linux-x64/bin/kibana & |
|
1 2 |
$ netstat -nplt | grep node tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 12471/node |
然后打开浏览器输入IP加端口5601即可访问,界面如下:

当这个画面打开之后,第一件事就是需要创建一个索引模式(index pattern),不然什么点击不了。另外,默认情况下,Kibana会连接运行在localhost的Elasticsearch。要连接其他 Elasticsearch实例,修改kibana.yml 里的 Elasticsearch URL,然后重启 Kibana。
但是当你创建一个默认索引时,发现都是灰色的,什么也创建不了。这是因为elasticsearch中没有索引,所以这里就一直是灰的,这个时候只要你的logstash和redis和elasticsearch都配置正确了,你只需要访问让你的Nginx让其产生日志输入到ES中,然后Kibana检测到有索引就行了。
可以访问nginx,要是有如下日志输出:

在刷新日志的时候,查看Redis队列,也可以查看到redis队列中的数据。
|
1 2 |
$ redis-cli -p 6379 llen logstash:redis (integer) 127 |
也可以访问elasticsearch的head插件,可以看到索引信息。

接下来就是创建你你需要的索引了。

如果创建成功,就会出现如下界面。

创建完成后,回到Discover选项,选项logstash-nginx-*就可以看到nginx的日志打入到了Kibana面板了。

到这里,ELK平台搭建就算完成了(如果不出日志,一定要看一下你的本地主机的时间是否正确,我就被这个问题坑了很多久,请注意),日志也都能通过面板展示出来了,当把这个平台搭建完成后,基本可以理解ELK了,接下来就可以单独学习各个组件的详细使用方式了。
生产环境中,基本上Logstash、Elaticsearch、Kibana都是通过Supervisor启动的,管理起来方便,建议使用。下一章就开启多个elasticsearch、以及使用supervisor启动、最后把结果输出成JSON格式展示在Kibana面板中。接着往下看。
Nginx日志输出为JSON格式
把Nginx日志的格式输出成JSON格式展示在Kibana面板,生产环境中基本都是这么使用。
配置Nginx
主要修改nginx的访问日志格式,这里定义成json格式,以便后面logstash更好的处理,建议生产环境也这样使用。在主配置/etc/nginx/nginx.conf文件中添加如下内容(注释其他日志格式):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
log_format json '{"@timestamp":"$time_iso8601",' '"host":"$server_addr",' '"clientip":"$remote_addr",' '"size":$body_bytes_sent,' '"responsetime":$request_time,' '"upstreamtime":"$upstream_response_time",' '"upstreamhost":"$upstream_addr",' '"http_host":"$host",' '"url":"$uri",' '"referer":"$http_referer",' '"agent":"$http_user_agent",' '"status":"$status"}'; |
在/etc/nginx/conf.d/default.conf中添加如下一行,定义nginx日志使用的格式,以及日志文件的位置。
|
1 |
access_log /var/log/nginx/access.log json; |
然后重新启动nginx
|
1 2 |
$ nginx -s stop $ nginx |
配置Logstash
修改Indexer角色的配置文件:logstash_indexer.conf
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
$ cat /usr/local/logstash-2.3.2/etc/logstash_indexer.conf input { redis { host => "localhost" data_type => "list" key => "logstash:redis" type => "redis-input" } } filter { json { source => "message" remove_field => "message" } } output { elasticsearch { hosts => ["localhost"] index => "logstash-nginx-%{+YYYY.MM.dd}" document_type => "nginx" # template => "/usr/local/logstash-2.3.2/etc/elasticsearch-template.json" workers => 1 flush_size => 20000 idle_flush_time => 10 } } |
删除elasticsearch老的数据
|
1 |
$ rm -fr /data/elasticsearch/* |
然后重启logstash_indexer.conf和elastisearch即可,继续刷新Nginx日志。
打开Kibana,应该会让你重新创建索引,如果没有问题会出现JSON格式的日志。

可以看出日志格式都是按照JSON格式给格式化了,方便查看和后续作图。