一、InnoDB缓冲池
1. 表空间编号
InnoDB存储引擎是使用表空间来存储页的,表空间又可以被分为系统表空间和独立表空间。为了方便管理,每个表空间都会有一个4字节的编号,值得注意的一点是,系统表空间的编号始终为0,InnoDB也会根据一定规则给其他独立表空间也编上号。
所以,当我们查看或修改某个页的数据的时候,实际上需要同时知道表空间的编号和该页的编号,也就是表空间号 + 页号的组合才能定位到某一个具体的页。同时,InnoDB每个页的编号也是占用4个字节,而在一个表空间内页的编号是不能重复的,4个字节是32个二进制位,也就是说:一个表空间最多拥有 2³² 个页,默认情况下一个页的大小为16KB,也就是说一个表空间最多存储 64TB 的数据。
总之,MySQL从磁盘加载数据到内存中最小单元是页,而定位数据页的方式就是通过“表空间号 + 页号”组合来的。同样在内存中定位数据页也是通过“表空间号 + 页号”来的。然后对于“表空间号”在表示上可能会看见有叫SPACE或TABLESPACE的;对于“页号”在表示上可能会看见有叫PAGE NO,PAGE ID,PAGE NUMBER的,反正只要知道都是一个意思就行了。
2. 缓存的重要性
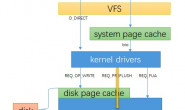
所谓的表空间只不过是InnoDB对文件系统上一个或几个实际文件的抽象,我们的数据说到底还是存储在磁盘上的。但是各位也都知道,磁盘的速度慢的跟乌龟一样,怎么能配得上“快如风,疾如电”的CPU呢?用户对数据库的最基本要求就是能高效的读取和存储数据,但是读写数据都涉及到与低速的设备交互,为了弥补两者之间的速度差异,所有数据库都有缓存池,用来管理相应的数据页,提高数据库的效率,当然也因为引入了这一中间层,数据库对内存的管理变得相对比较复杂。
MySQL服务器在处理客户端的请求时,当需要访问某个页的数据时,就会把完整的页的数据全部加载到内存中,也就是说即使我们只需要访问一个数据页的一条记录,那也需要先把整个页的数据加载到内存中。这是为了不必每次请求都去访问一下磁盘,那得多慢啊~
而对某个页的访问类型分为两种,一种是只读访问,一种是写入访问。只读访问好办,就是把磁盘上的页加载到内存中读而已;而如果需要修改该页的数据就有点尴尬了,首先会把数据写到内存中的页中,然后在某个合适的时刻将修改过的页同步到磁盘上,同步的时候断电咋办?数据就丢了么?当然不是了,凡是成熟的数据库系统都会有一套完整的机制来保证写入过程要么完整的完成,要么就把已经写入的数据恢复到之前没写的情况,总之数据是肯定不会丢失的。
3. 缓冲池内部结构
InnoDB维护一个称为缓冲池(Buffer Pool)的内存存储区域 ,主要用来存储访问过的数据页面,它就是向操作系统申请的一块连续的内存空间,通过一定的算法可以使这块内存得到有效的管理。它是数据库系统中拥有最大块内存的系统模块。Buffer Pool通常由数个内存块加上一组控制结构体对象组成,内存块的个数取决于buffer pool instance的个数,不过在MySQL 5.7版本中开始默认以128M(可配置)的chunk单位分配内存块,这样做的目的是为了支持buffer pool的在线动态调整大小。InnoDB存储引擎中数据的访问是按照页(也可以叫块,默认未16KB)的方式从数据库文件读取到Buffer Pool中的,然后在内存中用同样大小的内存空间来做一个映射。为了提高数据访问效率,数据库系统预先就分配了很多这样的空间,用来与文件中的数据进行交换。
Buffer Pool的每个内存块通过mmap的方式分配内存,因此你会发现,在实例启动时虚存很高,而物理内存很低。在Linux下,多个进程需要共享一片内存,可以使用mmap来分配和绑定,所以只提供给一个MySQL进程使用也是可以的。用mmap分配的内存都是虚存,在top命令中占用VIRT这一列,而不是RES这一列,只有相应的内存被真正使用到了,才会被统计到RES中,提高内存使用率。这样是为什么常常看到MySQL一启动就被分配了很多的VIRT,而RES却是慢慢涨上来的原因。这些大片的内存块又按照16KB划分为多个frame,用于存储数据页。虽然大多数情况下buffer pool是以16KB来存储数据页,但有一种例外:使用压缩表时,需要在内存中同时存储压缩页和解压页,对于压缩页,使用Binary buddy allocator算法来分配内存空间。例如我们读入一个8KB的压缩页,就从Buffer Pool中取一个16KB的block,取其中8KB,剩下的8KB放到空闲链表上;如果紧跟着另外一个4KB的压缩页读入内存,就可以从这8KB中分裂4KB,同时将剩下的4KB放到空闲链表上。
我们已经知道这个Buffer Pool其实是一片连续的内存空间,那现在就面临这个问题了:怎么将磁盘上的页缓存到内存中的Buffer Pool中呢?直接把需要缓存的页向Buffer Pool里一个一个往里怼么?不不不,为了更好的管理这些被缓存的页,InnoDB为每一个缓存页都创建了一些所谓的控制信息,这些控制信息包括该页所属的表空间编号、页号、页在Buffer Pool中的地址,一些锁信息以及LSN信息(锁和LSN这里可以先忽略),当然还有一些别的控制信息。
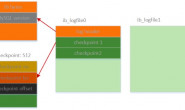
每个缓存页对应的控制信息占用的内存大小是相同的,我们就把每个页对应的控制信息占用的一块内存称为一个控制块吧,控制块和缓存页是一一对应的,它们都被存放到 Buffer Pool 中,其中控制块被存放到 Buffer Pool 的前边,缓存页被存放到 Buffer Pool 后边,所以整个Buffer Pool对应的内存空间看起来就是这样的:

控制块和缓存页之间的那个碎片是个什么呢?你想想啊,每一个控制块都对应一个缓存页,那在分配足够多的控制块和缓存页后,可能剩余的那点儿空间不够一对控制块和缓存页的大小,自然就用不到喽,这个用不到的那点儿内存空间就被称为碎片了。当然,如果你把Buffer Pool的大小设置的刚刚好的话,也可能不会产生碎片~
4. 缓冲池工作机制
当我们最初启动MySQL服务器的时候,需要完成对Buffer Pool的初始化过程,就是分配Buffer Pool的内存空间,把它划分成若干对控制块和缓存页。但是此时并没有真实的磁盘页被缓存到Buffer Pool中(因为还没有用到),之后随着程序的运行,会不断的有磁盘上的页被缓存到Buffer Pool中,那么问题来了,从磁盘上读取一个页到Buffer Pool中的时候该放到哪个缓存页的位置呢?或者说怎么区分Buffer Pool中哪些缓存页是空闲的,哪些已经被使用了呢?我们最好在某个地方记录一下哪些页是可用的,我们可以把所有空闲的页包装成一个节点组成一个链表,这个链表也可以被称作Free链表(或者说空闲链表)。因为刚刚完成初始化的Buffer Pool中所有的缓存页都是空闲的,所以每一个缓存页都会被加入到Free链表中,假设该Buffer Pool中可容纳的缓存页数量为n,那增加了Free链表的效果图就是这样的:

从图中可以看出,我们为了管理好这个Free链表,特意为这个链表定义了一个控制信息,里边儿包含着链表的头节点地址,尾节点地址,以及当前链表中节点的数量等信息。我们在每个Free链表的节点中都记录了某个缓存页控制块的地址,而每个缓存页控制块都记录着对应的缓存页地址,所以相当于每个Free链表节点都对应一个空闲的缓存页。
有了这个Free链表事儿就好办了,每当需要从磁盘中加载一个页到Buffer Pool中时,就从Free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的Free链表节点从链表中移除,表示该缓存页已经被使用了~
下面我们再来简单地看一下Buffer Pool的工作机制。根据我的理解,Buffer Pool两个最主要的功能:一个是加速读,一个是加速写。加速读呢? 就是当需要访问一个数据页面的时候,如果这个页面已经在缓存池中,那么就不再需要访问磁盘,直接从缓冲池中就能获取这个页面的内容。加速写呢?就是当需要修改一个页面的时候,先将这个页面在缓冲池中进行修改,记下相关的重做日志,这个页面的修改就算已经完成了。至于这个被修改的页面什么时候真正刷新到磁盘,这个是Buffer Pool后台刷新线程来完成的,后面会详细讲到。
在实现上面两个功能的同时,需要考虑客观条件的限制,因为机器的内存大小是有限的,所以MySQL的InnoDB Buffer Pool的大小同样是有限的,如果需要缓存的页占用的内存大小超过了Buffer Pool大小,也就是Free链表中已经没有多余的空闲缓存页的时候岂不是很尴尬,发生了这样的事儿该咋办?当然是把某些旧的缓存页从Buffer Pool中移除,然后再把新的页放进来喽~ 那么问题来了,移除哪些缓存页呢?
为了回答这个问题,我们还需要回到我们设立Buffer Pool的初衷,我们就是想减少和磁盘的I/O交互,最好每次在访问某个页的时候它都已经被缓存到Buffer Pool中了。假设我们一共访问了n次页,那么被访问的页已经在缓存中的次数除以n就是所谓的缓存命中率,我们的期望就是让缓存命中率越高越好~
怎么提高缓存命中率呢?InnoDB Buffer Pool采用经典的LRU算法来进行页面淘汰,以提高缓存命中率。当Buffer Pool中不再有空闲的缓存页时,就需要淘汰掉部分最近很少使用的缓存页。不过,我们怎么知道哪些缓存页最近频繁使用,哪些最近很少使用呢?呵呵,神奇的链表再一次派上了用场,我们可以再创建一个链表,由于这个链表是为了按照最近最少使用的原则去淘汰缓存页的,所以这个链表可以被称为LRU链表(Least Recently Used)。当我们需要访问某个页时,可以这样处理LRU链表:
- 如果该页不在Buffer Pool中,在把该页从磁盘加载到Buffer Pool中的缓存页时,就把该缓存页包装成节点塞到链表的头部。
- 如果该页在Buffer Pool中,则直接把该页对应的LRU链表节点移动到链表的头部。
也就是说,只要我们使用到某个缓存页,就把该缓存页调整到LRU链表的头部,这样LRU链表尾部就是最近最少使用的缓存页喽~ 所以当Buffer Pool中的空闲缓存页使用完时,到LRU链表的尾部找些缓存页淘汰就OK啦。这样处理起来虽然很简单,但问题却很多。比如你的一次全表扫描或一次逻辑备份就把热数据给冲完了,就会导致导致缓冲池污染问题!Buffer Pool中的所有数据页都被换了一次血,其他查询语句在执行时又得执行一次从磁盘加载到Buffer Pool的操作,而这种全表扫描的语句执行的频率也不高,每次执行都要把Buffer Pool中的缓存页换一次血,这严重的影响到其他查询对 Buffer Pool 的使用,严重的降低了缓存命中率 !所以InnoDB对于LRU链表的处理采用了划分逻辑区域来管理,具体看下嘛的LRU链表部分介绍。
另外,前面我们讲到页面更新是在缓存池中先进行的,那它就和磁盘上的页不一致了,这样的缓存页也被称为脏页(英文名:dirty page)。所以需要考虑这些被修改的页面什么时候刷新到磁盘?以什么样的顺序刷新到磁盘?当然,最简单的做法就是每发生一次修改就立即同步到磁盘上对应的页上,但是频繁的往磁盘中写数据会严重的影响程序的性能(毕竟磁盘慢的像乌龟一样)。所以每次修改缓存页后,我们并不着急立即把修改同步到磁盘上,而是在未来的某个时间点进行同步,由后台刷新线程依次刷新到磁盘,实现修改落地到磁盘。
但是如果不立即同步到磁盘的话,那之后再同步的时候我们怎么知道Buffer Pool中哪些页是脏页,哪些页从来没被修改过呢?总不能把所有的缓存页都同步到磁盘上吧,假如Buffer Pool被设置的很大,比方说300G,那一次性同步这么多数据岂不是要慢死!所以,我们不得不再创建一个存储脏页的链表,凡是在LRU链表中被修改过的页都需要加入这个链表中,因为这个链表中的页都是需要被刷新到磁盘上的,所以也叫FLUSH链表,有时候也会被简写为FLU链表。链表的构造和Free链表差不多,这就不赘述了。这里的脏页修改指的此页被加载进Buffer Pool后第一次被修改,只有第一次被修改时才需要加入FLUSH链表(代码中是根据Page头部的oldest_modification==0来判断是否是第一次修改),如果这个页被再次修改就不会再放到FLUSH链表了,因为已经存在。需要注意的是,脏页数据实际还在LRU链表中,而FLUSH链表中的脏页记录只是通过指针指向LRU链表中的脏页。并且在FLUSH链表中的脏页是根据oldest_lsn(这个值表示这个页第一次被更改时的lsn号,对应值oldest_modification,每个页头部记录)进行排序刷新到磁盘的,值越小表示要最先被刷新,避免数据不一致。
简单介绍了Buffer Pool的工作机制,我们现在来看Buffer Pool里面最重要的几个链表,FREE链表、LRU链表以及FLUSH链表。需要注意这几个链表之间的关系,如下图:

Free链表跟LRU链表的关系是相互流通的,页在这两个链表间来回置换。而FLUSH链表记录了脏页数据,也是通过指针指向了LRU链表,所以图中FLUSH链表被LRU链表包裹。
所以,总结一下。为了管理Buffer Pool,每个Buffer Pool Instance使用如下几个链表来管理:
- free链表:空闲内存页(块)列表,需要装载(缓存)磁盘上的数据页的时候,首先从此列表取内存块。
- lru链表:缓存了所有读入内存的数据页,包含三类。
- 已使用但未修改过的页面,可以从该列表中摘除,然后移到 free 链表中。
- 已修改还未刷新到磁盘的页面,其数据和磁盘上的数据已经不一致,称之为脏页。
- 已修改且已经刷新到磁盘的页面,可并为第一类。
- flush链表:记录了在LRU链表中被修改但还没有刷新到磁盘的数据页列表,就是所谓的脏页列表。FLUSH链表记录脏页是通过指针指向了LRU链表。
为了更好的管理Buffer Pool中的缓存页,除了上边提到的一些措施,InnoDB的还引进了其他的一些链表,比如:
- Unzip LRU链表用于管理解压页。
- Zip Clean链表用于管理存储没有被解压的压缩页。
- Zip Free链表用来管理被压缩的页等等。
反正是为了更好的管理这个Buffer Pool引入了各种链表,构造和我们介绍的链表都差不多。
4. LRU链表管理
InnoDB管理LRU链表的方式也是基于LRU算法的管理,但是比普通LRU算法要复杂很多。InnoDB将LRU链表根据midpoint位置从逻辑上按照一定比例分为两个区域(逻辑是指这两个区域其实还是一个链表,只是通过midpoint在逻辑上来区分这两个区域):一部分存储使用频率非常高的缓存页,称为为young区域(热数据),也可以称为new区域,在midpoint之前;另一部分存储使用频率不是很高的缓存页,称为为old区域(冷数据),在midpoint之后。简单的示意图如下:

所以把一个完整的LRU链表逻辑分成了young(new sublist)和old(old sublist)两个区域之后,每部分都有对应的头部和尾部。修改LRU链表的方式也就可以变一变了:
- 如果某个页第一次从磁盘加载到Buffer Pool中,则放到midpoint位置后,也就是old区域的头部。
- 如果该页已经在Buffer Pool中,则将其放到young区域的头部,也就是LRU链表的头部。
这就是所谓的“中点(midpoint)插入策略”,这样搞有啥好处呢?在没有空闲的缓存页时(首先从FREE链表申请页),我们可以从old区域中淘汰一些页,而不影响young区域中的缓存页。这样全表扫描的页虽然也会进入Buffer Pool中,但是由于首次缓存时只会放到old区域,young区域不受影响,也就是只会对Buffer Pool造成部分换血,而不是全部换血,这在一定程度上降低了全表扫描对Buffer Pool的缓存命中率的影响。
那这个划分成两个区域,也就是midpoint这个点放在链表的哪里合适呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,如下(支持动态修改):
|
1 2 3 4 5 6 7 |
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec) |
LRU 算法有以下的标准算法:
- 大概 3/8 的区域作为 old 区域,这些页是可能被驱逐的对象。剩下的 5/8 自然就是 young 区域的大小。
- 链表的中点(midpoint)就是我们所谓的 old 区域头部和 young 区域尾部的连接点,相当于一个界限。
- 新数据的读入首先会插入到 midpoint 位置后,也即是 old 区域的头部。
- 如果是 old 区域的数据被访问到了,这个页就会变成 young 区域,就会将数据页信息移动到 young 区域的头部。
- 在数据库的 Buffer Pool 里面,不管是 young 区域还是 old 区域的数据如果不会被访问到,最后都会被移动到链表的尾部作为牺牲者。
现在我们知道了首次从磁盘上加载到Buffer Pool的页会放到old区域,第二次访问该页的时候便会被放到young区域,这样的设计仍然无法解决大表扫描导致缓冲池污染问题,因为一个页中有很多条记录,也就是说一次大表扫描,这个页会被读多次,自然会移动到young区域头部(MySQL读数据虽然最小单元是按页从磁盘加载到内存,但是读记录确是从页中一条一条读取,每读一条记录就需要读一次数据页)。
InnoDB为了优化这个问题引入了一个间隔时间机制,当第二次访问old区域的某个缓存页时(该缓存页没有被淘汰掉),如果距离上一次访问的时间小于这个时间,那就不把这个缓存页放到young区域,这个过程称之为page not made young;而如果距离上一次访问的时间不小于这个时间,那就把这个缓存页放到young区域,这个过程称之为page made young。这样就可以降低在全表扫描时需要对页读取多次而对缓冲池的污染。InnoDB中这个间隔时间是由系统变量innodb_old_blocks_time控制的,如下:
|
1 2 3 4 5 6 7 |
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_old_blocks_time | 1000 | +------------------------+-------+ 1 row in set (0.01 sec) |
它的单位是毫秒,也就意味着如果在1秒内这个页被多次扫描,这些在old区域的页也不会被加入到young区域的。只有超过这1s,这个页还能在old区域存活下去,然后才有资格被移动到young区域。当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~
还有一个问题,对于young区域的缓存页来说,我们每次访问一个缓存页就要把它移动到LRU链表的头部,这样开销是不是太大啦,毕竟在young区域的缓存页都是热点数据,也就是可能被经常访问的,这样频繁的对LRU链表进行节点移动操作是不是不太好啊?是的,为了解决这个问题其实我们还可以提出一些优化策略,比如只有被访问的缓存页其于young区域的1/4(这个值可调节)之后,才会被移动到LRU链表头部,这样就可以降低调整LRU链表的频率,从而提升性能。
关于LRU链表的优化策略,还有很多,作为普通用户也没有必要了解太细。适可而止,想了解更多的优化知识,自己去看源码或者更多关于LRU链表的知识喽~ 另外,不同的大公司,可能会针对自己的业务对LRU链表进行自己的定制,优化是无穷尽的,但是千万别忘了我们的初心:尽量提高 Buffer Pool 的缓存命中率。
5. 缓冲池中页定位
我们前边说过,当我们需要访问某个页中的数据时,就会把该页加载到Buffer Pool中,如果该页已经在Buffer Pool中的话直接使用就可以了。那么问题也就来了,我们怎么知道该页在不在Buffer Pool中呢?难不成需要依次遍历Buffer Pool中各个缓存页么?一个Buffer Pool中的缓存页这么多都遍历完岂不是要累死?
再回头想想,我们其实是根据表空间号 + 页号来定位一个页的,也就相当于表空间号 + 页号是一个key,缓存页就是对应的value,怎么通过一个key来快速找着一个value呢?那肯定是哈希表了,复杂度O(1)。
所以我们可以用表空间号 + 页号作为key,缓存页作为value创建一个哈希表,在需要访问某个页的数据时,先从哈希表中根据表空间号 + 页号看看有没有对应的缓存页,如果有,直接使用该缓存页就好,如果没有,那就从Free链表中选一个空闲的缓存页,然后把磁盘中对应的页加载到该缓存页的位置。
二、缓冲池相关指标信息
InnoDB缓冲池将表的索引和数据进行缓存,缓冲池允许从内存直接处理频繁使用的数据,这加快了处理速度。在专用数据库服务器上,通常将多达80%的物理内存分配给InnoDB缓冲池。因为InnoDB的存储引擎的工作方式总是将数据库文件按页读取到缓冲池,每个页16k默认(innodb_page_size=16k),在MySQL 5.7中增加了32KB和64KB页面大小的支持,之前版本是不允许大于16k的;但你只能在初始化MySQL实例之前进行配置,一旦设置了一个实例的页面大小,就不能改变它,具体看innodb_page_size参数。
然后按最近最少使用(LRU)算法来保留在缓冲池中的缓存数据。如果数据库文件需要修改,总是首先修改在缓存池中的页(发生修改后,该页即为脏页),然后再按照一定的频率将缓冲池的脏也刷新到文件中。可以通过SHOW ENGINE INNODB STATUS来查看innodb_buffer_pool的具体使用情况。一个Buffer Pool可能会分成好几个Buffer Pool Instance,为了提高性能减少争用,在MySQL 5.7中,如果不显式设置innodb_buffer_pool_instances这个参数,当innodb buffer size大于1G的时候,就会默认会分成8个instances,如果小于1G,就只有1个instance。
缓冲池使用信息描述如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
mysql> show engine innodb status\G Per second averages calculated from the last 38 seconds(以下信息来之过去的38秒) ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 13218349056; Dictionary memory allocated 4014231 Buffer pool size 786432 Free buffers 8174 Database pages 710576 Old database pages 262143 Modified db pages 124941 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 6195930012, not young 78247510485 108.18 youngs/s, 226.15 non-youngs/s Pages read 2748866728, created 29217873, written 4845680877 160.77 reads/s, 3.80 creates/s, 190.16 writes/s Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 710576, unzip_LRU len: 118 I/O sum[134264]:cur[144], unzip sum[16]:cur[0] -------------- (...省略后边的许多状态) |
在Buffer pool size中可以看到页相关使用情况,如果能明白上面的原理部分,看下面的信息应该就很简单了。
Total memory allocated:为缓冲池分配的总内存(以字节为单位)。
Dictionary memory allocated:分配给InnoDB数据字典的总内存(以字节为单位)。
Buffer pool size:分配给缓冲池的页面总数量(数量*页面大小=缓冲池大小),默认每个Page为16k。
Free buffers:缓冲池中空闲列表的页面总数量(Buffer pool size – Database pages)。
Database pages:缓冲池中LRU链表的页面总数量,包含young区域和old区域,可以理解为已经使用的页面。
Old database pages:代表LRU链表old区域的节点数量。
Modified db pages:缓冲池中已经修改了的页数,所谓脏数据。也就是FLUSH链表中节点的数量。
Pages made young:代表从old区域移动到young区域的节点数量。
not young:代表old区域没有移动到young区域就被淘汰的节点数量,后边跟着移动的速率。
youngs/s:在old区域坚持到了1s,进入到young区域的页。
non-youngs/s:在old区域没有坚持到了1s,于是被刷出去了的页。
Pages read、created、written:代表InnoDB读取,创建,写入了多少页。后面分别跟着读取、创建、写入的速率。
LRU len:代表LRU链表中节点的数量。
unzip_LRU:代表非16K大小的页的数量,这些非16K大小的页都是被unzip_LRU链表管理的,就是被压缩的页。
对于youngs/s值正常不可能一直很高,因为热数据区就那么大,不可能一直往里调。此值过大的原因,可以考虑是不是pct过大(pct过大,冷区大,热区小,time过小,就容易young进去)。对于non-youngs/s的值过大原因,可能存在严重的全表扫描(频繁的被刷出来)、可能是pct设置的过小(冷数据区就很小,来一点数据就刷出去了)、可能是time设置的过大(没坚持到1s,被刷出去了)。
从信息可以看出,这里一共分配了786432*16/1024/1024=12G内存的缓冲池,空闲8174个页面,已经使用了778258个页面(为什么和Database pages显示的710576不符合?),不经常访问的数据页有262143个(一般占用内存的1/3),脏页的页面有124941个,这些数据能分析当前数据库的压力值。
另外在information_schema.INNODB_BUFFER_POOL_STATS系统视图中记录着Buffer Pool相关信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
mysql> select * from INNODB_BUFFER_POOL_STATS limit 1\G *************************** 1. row *************************** POOL_ID: 0 POOL_SIZE: 8191 FREE_BUFFERS: 1024 DATABASE_PAGES: 7159 OLD_DATABASE_PAGES: 2622 MODIFIED_DATABASE_PAGES: 0 PENDING_DECOMPRESS: 2 PENDING_READS: 0 PENDING_FLUSH_LRU: 0 PENDING_FLUSH_LIST: 0 PAGES_MADE_YOUNG: 4571 PAGES_NOT_MADE_YOUNG: 2935549 PAGES_MADE_YOUNG_RATE: 0 PAGES_MADE_NOT_YOUNG_RATE: 0 NUMBER_PAGES_READ: 23890 NUMBER_PAGES_CREATED: 16107 NUMBER_PAGES_WRITTEN: 22910 .......... |
在information_schema.INNODB_BUFFER_PAGE系统视图(引擎MEMORY)中记录着Buffer Pool中页的状态信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
mysql> select * from information_schema.INNODB_BUFFER_PAGE where SPACE <> 0 limit 1\G *************************** 1. row *************************** POOL_ID: 0 BLOCK_ID: 0 SPACE: 327 PAGE_NUMBER: 1036 PAGE_TYPE: INDEX FLUSH_TYPE: 0 FIX_COUNT: 0 IS_HASHED: NO NEWEST_MODIFICATION: 0 OLDEST_MODIFICATION: 0 ACCESS_TIME: 2195208700 TABLE_NAME: `employees`.`salaries` INDEX_NAME: PRIMARY NUMBER_RECORDS: 468 DATA_SIZE: 14976 COMPRESSED_SIZE: 0 PAGE_STATE: FILE_PAGE IO_FIX: IO_NONE IS_OLD: YES FREE_PAGE_CLOCK: 18667 1 row in set (0.05 sec) |
视图中记录了SPACE ID和PAGE ID,相关字段信息基本也都见名知义了,其中COMPRESSED_SIZE字段表示你如果启用了表压缩功能,这里就会显示压缩页大小(在Buffer Pool中有相关链管理压缩页)。我在查询时过滤了SPACE=0的页,这些都是系统表空间页占用。
主要说一下NEWEST_MODIFICATION和OLDEST_MODIFICATION字段,其中OLDEST记录了这个页第一次被修改时的LSN号是多少,而NEWEST记录了这个页最新一次被修改时的LSN号是多少。在上面已经介绍了OLDEST的作用是干什么的了。
另外在information_schema.INNODB_BUFFER_PAGE_LRU系统视图(引擎MEMORY)中记录着LRU链表中相关页信息,格式与INNODB_BUFFER_PAGE系统视图相同。
Note
这个几张表在线上最好还是不要做相关查询操作,因为需要即时去收集缓冲池信息,而缓冲池又是比较热的这样一个资源,所以代价还是蛮大的。特别当缓冲池稍微大点的时候,可能会出现几秒钟的夯住,风险很大。
三、数据页访问机制
下面我们来看一下一个数据页的访问流程。
- 当访问的页面在缓存池中命中,则直接从缓冲池中访问该页面。另外为了避免查询数据页时扫描LRU,还为每个buffer pool instance维护了一个page hash,通过space id和page id可以直接找到对应的page。一般情况下,当我们需要读入一个Page时,首先根据space id和page id找到对应的buffer pool instance。然后查询page hash,如果page hash中没有,则表示需要从磁盘读取。
- 如果没有命中,则需要将这个页面从磁盘上加载到缓存池中,因此需要在缓存池中的空闲列表中找一个空闲的内存块来缓存这个从磁盘读入的页面。
- 但存在空闲内存块被使用完的情况,不保证一定有空闲的内存块。假如空闲列表为空,没有空闲的内存块,则需要想办法去产生空闲的内存块。
- 首先去LRU列表中找可以替换的内存页面,查找方向是从列表的尾部开始找,如果找到可以替换的页面,将其从LRU列表中摘除,加入空闲列表,然后再去空闲列表中找空闲的内存块。第一次查找最多只扫描100个页面,循环进行到第二次时,会查找深度就是整个LRU列表。这就是LRU列表中的页面淘汰机制。
- 如果在LRU列表中没有找到可以替换的页,则进行单页刷新,将脏页刷新到磁盘之后,然后将释放的内存块加入到空闲列表。然后再去空闲列表中取。为什么只做单页刷新呢?因为这个函数的目的是获取空闲内存页,进行脏页刷新是不得已而为之,所以只会进行一个页面的刷新,目的是为了尽快的获取空闲内存块。
因为空闲列表是一个公共的列表,所有的用户线程都可以使用,存在争用的情况。因此,自己产生的空闲内存块有可能会刚好被其他线程所使用,所以用户线程可能会重复执行上面的查找流程,直到找到空闲的内存块为止。
通过数据页访问机制,可以知道其中当无空闲页时产生空闲页就成为一个必须要做的事情了。如果需要刷新脏页来产生空闲页面或者需要扫描整个LRU列表来产生空闲页面的时候,查找空闲内存块的时间就会延长,这个是一个bad case,是我们希望尽量避免的。因此,innodb buffer pool中存在大量可以替换的页面,或者free列表中一直存在着空闲内存块,对快速获取到空闲内存块起决定性的作用。在innodb buffer pool的机制中,是采用何种方式来产生的空闲内存块,以及可以替换的内存页的呢?这就是我们下面要讲的内容——通过后台刷新机制来产生空闲的内存块以及可以替换的页面。
四、缓冲池刷新策略
InnoDB会在后台执行某些任务,包括从缓冲池刷新脏页(那些已更改但尚未写入数据库文件的页)。
当启用innodb_max_dirty_pages_pct_lwm(默认值0)参数时,表示启用了脏页面预刷新行为,以控制脏页面占比。也是为了防止脏页占有率超过innodb_max_dirty_pages_pct(默认值75%)的设定值。默认禁用“预刷新”行为。如果当脏页的占有率达到了innodb_max_dirty_pages_pct的设定值的时候,InnoDB就会强制刷新buffer pool pages。另外当Free链表小于innodb_lru_scan_depth值时也会触发脏页刷新机制,innodb_lru_scan_depth参数是控制Free链表中可用页的数量,该值默认为1024。
后台刷新的动作由后台刷新协调线程触发,该线程的所有工作内容均由buf_flush_page_cleaner_coordinator函数完成,我们后面简称它为协调函数。接下来,来看后台刷新协调函数的主体流程。
- 调用page_cleaner_flush_pages_recommendation建议函数,对每个缓冲池实例生成脏页刷新数量的建议。在执行刷新之前,会用建议函数生成每个buffer pool实例需要刷新多少个脏页的建议。
- 生成刷新建议之后,通过设置事件的方式,向刷新线程(Page Cleaner线程)发出刷新请求。后台刷新线程在收到请求刷新的事件后,会执行pc_flush_slot函数对某个缓冲池进行刷新,刷新的过程首先是对LRU链表进行刷新,执行的函数为buf_flush_LRU_list,完成LRU链表的刷新之后,就会根据建议函数生成的建议对脏页列表进行刷新,执行的函数为buf_flush_do_batch。
- 后台刷新的协调线程会作为刷新调度总负责人的角色,它会确保每个buffer pool都已经开始执行刷新。如果哪个buffer pool的刷新请求还没有被处理,则由刷新协调线程亲自刷新,且直到所有的buffer pool instance都已开始/进行了刷新,才退出这个while循环。
- 当所有的buffer pool instance的刷新请求都已经开始处理之后,协调函数(或协调线程)就等待所有buffer pool instance的刷新的完成,等待函数为pc_wait_finished。如果这次刷新的总耗时超过4000ms,下次循环之前,会在数据库的错误日志记录相关的超时信息。它期望每秒钟对buffer pool进行一次刷新调度。如果相邻两次刷新调度的间隔超过4000ms ,也就是4秒钟,MySQL的错误日志中会记录相关信息,意思就是“本来预计1000ms的循环花费了超过4000ms的时间。
前面我们反复讲到,每个buffer pool需要刷新多少页面是由建议函数生成的,它在做刷新建议的时候,具体考虑了哪些因素?现在我们来详细解析。
在讲这段内容之前,我们先来了解两个参数:innodb_io_capacity与innodb_io_capacity_max,这两个参数大部分朋友都不陌生,设置这个参数的目的,是告诉MySQL数据库,它所在服务器的磁盘的随机IO能力。MySQL数据库目前还没有去自己评估服务器磁盘IO能力的功能,所以磁盘io能力大小由这个参数提供,以便让数据库知道磁盘的实际IO能力。这个参数将直接影响建议刷新的页面的数量。
建议函数它会计算当前的脏页刷新平均速度(也就是一秒钟刷新了多少脏页)以及重做日志的生成平均速度。但这个函数并不是每次被调用时,都计算一次平均速度。它是多久计算一次的呢?这个是由数据库参数innodb_flushing_avg_loops来决定的,默认是30,当这个函数被调用了30次之后或者经过30秒之后,重新计算一次平均值。我们暂且简单理解为30秒钟。计算规则是当前的平均速度加上最近30秒钟期间的平均速度再除以2得出新的平均速度。两个平均值相加再平均,得出新的平均值。这样的平均值能明显的体现出最近30秒的速度的变化。
如何计算刷新数据页的平均速度以及redo日志的产生平均速度?

简单地看一下这部分代码,主要请关注这个if条件:当循环次数达到innodb_flush_avg_loops时或者经历的时间达到该值时,才进行新的平均值的计算。因此,大家清楚了这个参数的含义,是用来指明隔多久计算一次平均值。平均值计算规则就是新平均速度=(当前的平均速度+最近这段期间平均速度)%2。
接下来,它会根据innodb buffer pool的脏页百分比来计算innodb_io_capacity的百分比。然后会根据重做日志中的活跃日志量的大小,也就是lsn的age,最近生成量,占重做日志文件大小的百分比来计算innodb_io_capacity的百分比。调用相关函数根据脏页百分比来计算io_capacity的百分比,用变量pct_for_dirty保存,然后根据活跃日志量的大小来计算io_capacity的百分比,用变量pct_for_lsn来保存,这个值后面会被是使用到,用来决定每个buffer pool是建议刷新相同的数量的脏页,还是刷新不同的数量。当pct_for_lsn<30的时候,建议每个buffer刷新相同数量的页面。否则,建议刷新不同数量的页面。最后比较这两个变量的大小,大的值作为最终的io_capacity的百分比,用变量pct_total保存。假如计算出来的得到pctl_total为90,而数据库参数innodb_io_capacity设置为1000,则根据这两个因素再结合所设置的磁盘io能力,得出的建议就为刷新900个脏页,所以innodb_io_capacity参数也是刷新多少的一个重要参数。接下来我们将来看看是如何具体跟据这两项来计算io_capacity的百分比的。
如何根据脏页百分比来计算innodb_io_capacity百分比?
首先获取缓存池的脏页百分比,然后根据这个值进行判断。如果参数最大脏页百分比的低水位设置为0(默认值),当dirty_pct大于参数innodb_max_dirty_pages_pct(默认值75%),则返回100,否则返回0。如果设置了最大脏页百分比的低水位,当脏页百分比超过该值时,则返回相应的比例。当脏页百分比越接近最大脏页百分比,返回比例越接近100。否则为0。
如何根据重做日志活跃日志量来计算innodb_io_capacity百分比?
如果活跃日志量占日志文件大小的百分比小于参数innodb_adaptive_flushing_lwm,即自适应刷新的低水位,默认是10,则直接返回0。如果没有设置自适应刷新参数innodb_adaptive_flushing,(InnoDB 1.0引入的参数,自适应刷新,就是我们这里讲的刷新方式。旧的刷新方式时只有脏页在缓冲池中占的比例大于innodb_max_dirty_pages_pct参数时就会刷新100个脏页),默认为on,则需要等待活跃的日志量大于max_async_age的值,才会返回相应的百分比,否则返回0。可以简单的理解为,如果没有开启自适应刷新,则必须等待活跃日志量的过大,大到存在危害数据库的可用性风险时,才开始考虑基于活跃日志量的大小来进行脏页刷新。如果开启了自适应刷新,活跃日志量所占百分比大于自适应刷新的低水位时,返回相应的百分比。
然后,会根据前面计算的重做日志生成的平均速度,来计算建议每个buffer pool instance刷新多少脏页以及所有pool buffer的刷新总量。之所以会基于这个因素来考虑,我认为是这样的:新产生的重做日志是活跃的重做日志,根据活跃日志的生成速度来计算需要刷新的脏页的数量,从而将使活跃日志的过期速度跟生成速度达到一个均衡,这样控制了活跃的重做日志在一个正常的范围,保障了重做日志文件一直有可以使用的空间,不然就会有问题(可以看MySQL InnoDB checkpoint)。在这里简单说明一下活跃的重做日志跟不活跃的重做日志的区别:活跃日志是指其记录的被修改的脏页还没有被刷新到磁盘,当MySQL实例crash之后,需要使用这些日志来做实例恢复。
如何计算每个Buffer Pool Instance需要刷新的页面?
首先,根据前面计算得出的lsn_avg_rate,即重做日志产生的平均速度,计算出一个target_lsn号。
然后从每一个buffer pool的脏页列表的队尾开始取出脏页,将脏页的oldest_modifiaction(最小的lsn)跟target_lsn进行比较,这里简单的说明一下脏页的oldest_modification的含义,它表示的是脏页第一次修改时的lsn号,也就是脏页的最小lsn号。如果它小于target_lsn,然后将其作为刷新对象进行计数,否则,退出这个buffer pool内的循环。因为刷新列表是按照脏页的最小lsn号进行排序的,前面的脏页的最小lsn都大于target_lsn ,所以不需要再继续找下去。
从上面的计算方式可以看出,当重做日志生成的平均速度越大,target_lsn就越大。同时,如果buffer_pool中的脏页的oldest_modition小于target_lsn的数量越多,也就是老的脏页越多,被建议刷新的页面就越多。
再接下来,通过上面的计算,我们从不同维度分别得出三个建议刷新的数量:分别为当前的脏页刷新的平均速度,也就是一秒钟刷新了多少脏页;根据脏页百分比,以及活跃日志量的大小,以及所设置的innodb_io_capacity参数所得出建议刷新的数量;以及根据重做日志产生速度计算得出的建议刷新数量。将这三个值相加之后再平均,得出的就是考虑了上面所有因素的一个综合建议,由变量n_pages保存。接下来,这个建议刷新的总量n_pages会跟innodb_io_capacity_max这个参数进行比较,也就是建议刷新的总量最大不能超过所设置的磁盘最大随机io能力。
最后,生成最终的刷新建议。生成最终的刷新建议时,会考虑当前数据库的活跃日志量的大小,当前活跃日志比较少的时候,认为重做日志文件有足够可以使用的空间(以变量pct_for_lsn小于30为依据),则不需要考虑每个buffer pool之间的脏页年龄分布不均的情况,每个buffer pool刷新相同的数量,数量就刷新总量除以buffer pool的个数。如果活跃日志比较多(以变量pct_for_lsn大于等于30为依据),则需要考虑脏页的年龄在每个buffer pool的分布不同,每个buffer刷新不同的数量的脏页,老的脏页比较多的buffer pool instance刷新的数量也就多。
生成最终刷新建议后的刷新逻辑?
当生成刷新建议之后,就设置刷新请求事件,请求刷新线程进行脏页批量刷新。请求函数pc_request也很简单。
- 将所有buffer pool instances的刷新状态设置为PAGE_CLEANER_STATE_REQUESTED,即申请刷新。
- 通过设置事件,唤醒/触发page cleaner线程调用pc_flush_slot函数来进行buffer pool的批量刷新。
Page_cleaner线程收到刷新请求之后,就开始进行批量刷新。函数为pc_flush_slot。

- 寻找一个状态为申请刷新的缓存池实例,然后选为刷新对象,将状态修改为flushing.。然后执行后面的刷新。
- 执行buf_flush_LRU_list函数进行LRU列表的刷新。
- 执行buf_flush_do_batch批量刷新脏页列表,该buffer pool instance建议刷新的数量slot->n_pages_requested作为该函数参数值,也就是依据建议刷新的页面数来进行刷新。
对于LRU列表的刷新的函数buf_flush_LRU_list将scan_depth变量传递最终传递给buf_flush_LRU_list_batch函数,在通常情况下,可以简单的理解scan_depth的值来自于数据库参数innodb_lru_scan_deptch(简单理解innodb_lru_scan_depth参数控制LRU列表中可用页的数量,该值默认为1024)参数。接下来看buf_flush_LRU_list_batch函数,这个函数一个重要点就是如果Free链表的长度大于innodb_lru_scan_depth参数值,则终止内部循序。否则就往下走,然后就该判断如果是一个可替换的页,则将从LRU链表中摘除,其加入Free链表。如果是脏页,则进行刷新,直到满足小于innodb_lru_scan_depth的条件则终止循环体。由此我们可以看出innodb_lru_scan_depth参数,在此起非常关键的作用,实际上也直接影响了buffer bool instance中的Free链表的长度。
刷新协调函数是执行一个刷新循环的最后一步,就是设置事件等待,等待所有buffer pool instance刷新完成的事件触发。刷新完成之后,然后开始下一轮循环,如果刷新在1秒之内完成,则刷新协调线程会有短暂的sleep才会发起下一次刷新。期望是1秒钟进行一次所有buffer pool instance的批量刷新。
五、配置InnoDB缓冲池大小
你可以配置InnoDB缓冲池的各个方面来提高性能。
- 理想情况下,你将缓冲池的大小设置为尽可能大的值(70%-80%)。缓冲池越大,InnoDB内存数据库的行为越多,从磁盘读取数据一次,然后在后续读取期间从内存访问数据。
- 对于具有大内存的64位系统,你可以将缓冲池拆分成多个实例(默认8个),以最大限度地减少并发操作中内存结构的争用。
1. 在线配置InnoDB缓冲池大小
缓冲池支持脱机和联机两种配置方式,当增加或减少innodb_buffer_pool_size时,操作以块(chunk)形式执行。块大小由innodb_buffer_pool_chunk_size配置选项定义,默认值128M。
在线配置InnoDB缓冲池大小,innodb_buffer_pool_size配置选项可以动态使用设置SET声明,让你调整缓冲池无需重新启动服务器。例如:
|
1 |
mysql> SET GLOBAL innodb_buffer_pool_size=8589934592; |
缓冲池大小配置必须始终等于innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数。如果配置innodb_buffer_pool_size为不等于innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数,则缓冲池大小将自动调整为等于或不小于指定缓冲池大小的innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数。
在以下示例中, innodb_buffer_pool_size设置为8G,innodb_buffer_pool_instances设置为16,innodb_buffer_pool_chunk_size是128M,这是默认值。8G是一个有效的innodb_buffer_pool_size值,因为它是innodb_buffer_pool_instances=16乘以innodb_buffer_pool_chunk_size=128M的倍数。
|
1 2 3 4 5 6 7 |
mysql> select 8*1024 / (16*128); +-------------------+ | 8*1024 / (16*128) | +-------------------+ | 4.0000 | +-------------------+ 1 row in set (0.00 sec) |
如果innodb_buffer_pool_size设置为9G,innodb_buffer_pool_instances设置为16,innodb_buffer_pool_chunk_size是128M,这是默认值。在这种情况下,9G不是innodb_buffer_pool_instances=16*innodb_buffer_pool_chunk_size=128M的倍数 ,所以innodb_buffer_pool_size被调整为10G,这是不小于指定缓冲池大小的下一个innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances的倍数。
2. 监控在线缓冲池调整大小进度
该Innodb_buffer_pool_resize_status参数报告缓冲池大小调整的进展。例如:
|
1 2 3 4 5 6 7 |
mysql> SHOW STATUS WHERE Variable_name ='InnoDB_buffer_pool_resize_status'; +----------------------------------+-------+ | Variable_name | Value | +----------------------------------+-------+ | Innodb_buffer_pool_resize_status | | +----------------------------------+-------+ 1 row in set (0.01 sec) |
3. 配置InnoDB缓冲池块(chunk)大小
innodb_buffer_pool_chunk_size可以在1MB(1048576字节)单位中增加或减少,但只能在启动时,在命令行字符串或MySQL配置文件中进行修改。
|
1 2 |
[mysqld] innodb_buffer_pool_chunk_size = 134217728 |
修改innodb_buffer_pool_chunk_size时适用以下条件:
- 如果新innodb_buffer_pool_chunk_size值乘以innodb_buffer_pool_instances大于初始化缓冲池大小时, innodb_buffer_pool_chunk_size则截断为innodb_buffer_pool_size / innodb_buffer_pool_instances。
例如,如果缓冲池初始化大小为2GB(2147483648字节), 4个缓冲池实例和块大小1GB(1073741824字节),则块大小将被截断为等于innodb_buffer_pool_size / innodb_buffer_pool_instances,值为:
|
1 2 3 4 5 6 7 |
mysql> select 2147483648 / 4; +----------------+ | 2147483648 / 4 | +----------------+ | 536870912.0000 | +----------------+ 1 row in set (0.00 sec) |
- 缓冲池大小必须始终等于或不小于innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的倍数。如果更改innodb_buffer_pool_chunk_size,innodb_buffer_pool_size则会自动调整为等于或不小于当前缓冲池大小的innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances的倍数。缓冲池初始化时会发生调整。
更改时应小心innodb_buffer_pool_chunk_size,因为更改此值可以增加缓冲池的大小,如上面的示例所示。在更改innodb_buffer_pool_chunk_size之前,计算innodb_buffer_pool_size以确保生成的缓冲池大小是可接受的。
4. 在线调整缓冲池内部大小机制
调整大小的操作由后台线程执行,当增加缓冲池的大小时,调整大小操作:
- 添加页面个数chunks(chunks多少由innodb_buffer_pool_chunk_size定义)。
- 覆盖哈希表,列表和指针以在内存中使用新的地址。
- 将新页面添加到空闲列表中。
PS:当这些操作正在进行时,阻止其他线程访问缓冲池。
当减小缓冲池的大小时,调整大小操作:
- 对缓冲池进行碎片整理并提取空闲页面。
- 删除页面个数chunks(chunks多少由innodb_buffer_pool_chunk_size定义)。
- 转换哈希表,列表和指针以在内存中使用新的地址。
在这些操作中,只有对缓冲池进行碎片整理和撤销页面才允许其他线程同时访问缓冲池。
InnoDB在调整缓冲池大小之前,应完成通过API执行的活动事务和操作。启动调整大小操作时,在所有活动事务完成之前,操作都不会启动。一旦调整大小操作进行中,需要访问缓冲池的新事务和操作必须等到调整大小操作完成,但是允许在缓冲池进行碎片整理时缓冲池的并发访问。缓冲池大小减少时页面被撤销,允许并发访问的一个缺点是在页面被撤回时可能会导致可用页面暂时不足。
六、配置多个缓冲池实例
前面说过了,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,为了保护缓存页可能会对缓存页进行加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表等等,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool的个数。
|
1 |
innodb_buffer_pool_instances = 2 |
这样就表明我们要创建2个Buffer Pool。那每个Buffer Pool实际占多少内存空间呢?其实使用这个公式算出来的:
|
1 |
innodb_buffer_pool_size/innodb_buffer_pool_instances |
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的。InnoDB的规定,Buffer Pool 的大小小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。在MySQL 5.7中,如果不显式设置innodb_buffer_pool_instances这个参数,当innodb buffer size大于1G的时候,就会默认会分成8个instances,如果小于1G,就只有1个instance。
七、配置InnoDB缓冲池预读
InnoDB在io的优化上有个比较重要的特性为预读,预读请求是一个i/o请求,它会异步地在缓冲池中预先回迁多个页面,预计很快就会需要这些页面,这些请求在一个范围内引入所有页面。InnoDB以64个page为一个extent,那么InnoDB的预读是以page为单位还是以extent?
这样就进入了下面的话题,InnoDB使用两种预读算法来提高I/O性能:线性预读(linear read-ahead)和随机预读(randomread-ahead)
为了区分这两种预读的方式,我们可以把线性预读放到以extent为单位,而随机预读放到以extent中的page为单位。线性预读着眼于将下一个extent提前读取到buffer pool中,而随机预读着眼于将当前extent中的剩余的page提前读取到buffer pool中。
- 线性预读(linear read-ahead)
它可以根据顺序访问缓冲池中的页面,预测哪些页面可能需要很快。通过使用配置参数innodb_read_ahead_threshold,通过调整触发异步读取请求所需的顺序页访问数,可以控制Innodb执行提前读操作的时间。在添加此参数之前,InnoDB只会计算当在当前范围的最后一页中读取整个下一个区段时是否发出异步预取请求。
线性预读方式有一个很重要的变量控制是否将下一个extent预读到buffer pool中,通过使用配置参数innodb_read_ahead_threshold,可以控制Innodb执行预读操作的时间。如果一个extent中的被顺序读取的page超过或者等于该参数变量时,Innodb将会异步的将下一个extent读取到buffer pool中,innodb_read_ahead_threshold可以设置为0-64的任何值,默认值为56,值越高,访问模式检查越严格。
|
1 2 3 4 5 6 7 |
mysql> show global variables like '%innodb_read_ahead_threshold%'; +-----------------------------+-------+ | Variable_name | Value | +-----------------------------+-------+ | innodb_read_ahead_threshold | 56 | +-----------------------------+-------+ 1 row in set (0.00 sec) |
例如,如果将值设置为48,则InnoDB只有在顺序访问当前extent中的48个pages时才触发线性预读请求,将下一个extent读到内存中。如果值为8,InnoDB触发异步预读,即使程序段中只有8页被顺序访问。你可以在MySQL配置文件中设置此参数的值,或者使用SET GLOBAL需要该SUPER权限的命令动态更改该参数。
在没有该变量之前,当访问到extent的最后一个page的时候,InnoDB 会决定是否将下一个extent放入到buffer pool中。
- 随机预读(randomread-ahead)
随机预读方式则是表示当同一个extent中的一些page在buffer pool中发现时,Innodb会将该extent中的剩余page一并读到buffer pool中,由于随机预读方式给Innodb code带来了一些不必要的复杂性,同时在性能也存在不稳定性,在5.5中已经将这种预读方式废弃。要启用此功能,请将配置变量innodb_random_read_ahead设置为ON。
|
1 2 3 4 5 6 7 |
mysql> show global variables like '%innodb_random_read_ahead%'; +--------------------------+-------+ | Variable_name | Value | +--------------------------+-------+ | innodb_random_read_ahead | OFF | +--------------------------+-------+ 1 row in set (0.01 sec) |
在监控Innodb的预读时候,我们可以通过SHOW ENGINE INNODB STATUS命令显示统计信息,通过Pages read ahead和evicted without access两个值来观察预读的情况,或者通过两个状态值,以帮助您评估预读算法的有效性。
|
1 2 3 4 5 6 7 8 9 |
mysql> show global status like '%Innodb_buffer_pool_read_ahead%'; +---------------------------------------+-------+ | Variable_name | Value | +---------------------------------------+-------+ | Innodb_buffer_pool_read_ahead_rnd | 0 | | Innodb_buffer_pool_read_ahead | 0 | | Innodb_buffer_pool_read_ahead_evicted | 0 | +---------------------------------------+-------+ 3 rows in set (0.00 sec) |
而通过SHOW ENGINE INNODB STATUS得到的Pages read ahead和evicted without access则表示每秒读入和读出的pages:Pages read ahead 1.00/s, evicted without access 9.99/s。
当微调innodb_random_read_ahead设置时,此信息可能很有用 。
八、配置InnoDB缓冲池刷新
上面详细说了缓冲池刷新机制,简单来说基本原理可以总结如下:
当启用innodb_max_dirty_pages_pct_lwm(默认值0)参数时,表示启用了脏页面预刷新行为,以控制脏页面占比。也是为了防止脏页占有率超过innodb_max_dirty_pages_pct(默认值75%)的设定值。默认禁用“预刷新”行为。如果当脏页的占有率达到了innodb_max_dirty_pages_pct的设定值的时候,InnoDB就会强制刷新buffer pool pages。
另外在MySQL 5.6新加入一个参数innodb_lru_scan_depth,官方解释说此参数是一个影响对缓冲池刷新操作算法和启发式的参数。它指定每个缓冲池实例中的LRU链表被page_cleaner扫描的深度,page_cleaner通过扫描LRU链表来查找脏页进行刷新。简单理解就是innodb_lru_scan_depth控制LRU链表中可用页(可被替换)的数量,该值默认为1024,也即是“缓冲池实例 * 1024”,所以设置此参数时不能误以为是整个缓冲池扫描深度,最好参考innodb_io_capacity参数来设置。
InnoDB采用一种基于redo log的最近生成量(活跃日志量的大小,也就是lsn的age)和脏页刷新平均速度(一秒刷新了多少次)及innodb_io_capacity参数的算法来决定刷新脏页数量。这样的算法可以保证数据库的刷新不会影响到数据库的性能,也能保证数据库buffer pool中的数据的脏数据的占用比。这种自动调整刷新速率有助于避免过多的缓冲池刷新限制了普通读写请求可用的I/O容量,从而避免吞吐量突然下降,但还是对正常IO有影响。内部基准测试显示,该算法随着时间的推移可以显著提高整体吞吐量。这种算法是经得住考验的,所以说千万不要随便设置,最好是默认值。
配置参数innodb_flush_neighbors(刷新邻接页),innodb_lru_scan_depth可以让你微调缓冲池刷新过程的某些方面,这些选项主要是帮助写密集型的工作负载。如果DML操作较为严重,如果没有较高的值,则刷新可能会下降,会导致缓冲池中的内存过多。或者,如果这种机制过于激进,磁盘写入将会使你的I/O容量饱和,理想的设置取决于你的工作负载,数据访问模式和存储配置(例如数据是否存储在HDD或SSD设备上)。
InnoDB存储引挚提供了flush Neighbor page(刷新邻接页)的特性。其工作原理为:当刷新一个脏页时,InnoDB存储引挚会检测该页所在区(extent)的所有页,如果是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个IO写入操作合并为一个IO操作,故该工作机制在传统的机械硬盘下有着显著的优势。但需要考虑到下面两个问题:
- 是不是可能将不怎么脏的页进行了写入,而该页之后又会很快变成脏页?
- 固态硬盘有着较高的IOPS,是否还需要这个特性?
为此,InnoDB存储引挚从1.2.x版本开始提供了参数innodb_flush_neighbors,用来控制是否开启这个特性。对于传统的机械硬盘建议开启该特性,而对于固态硬盘有着超高的IOPS性能,则建议将该参数设置为0,即关闭此特性。
InnoDB对于具有不断繁重工作负载的系统或者工作负载波动很大的系统,可以使用下面几个配置选项来调整表的刷新行为:
innodb_adaptive_flushing_lwm:默认值10,指定重做日志容量的“ 低水位 ”百分比,当该阈值越过时,InnoDB即使没有开启innodb_adaptive_flushing选项也会自动启用自适应刷新。
innodb_max_dirty_pages_pct_lwm:默认值0,InnoDB尝试从缓冲池中刷新数据,以使脏页面的百分比不超过innodb_max_dirty_pages_pct参数的值(默认值为75)。该innodb_max_dirty_pages_pct_lwm选项是用来指定“ 低水位 ”值,其表示使用预刷新来控制脏页比例的百分比,也就是脏页比例达到innodb_max_dirty_pages_pct_lwm的值就会开始刷新脏页到磁盘,防止脏页的百分比达到innodb_max_dirty_pages_pct的值,innodb_max_dirty_pages_pct_lwm默认0,禁用“ 预刷新”行为。
innodb_io_capacity_max:默认2000,如果刷新动作远远落后,InnoDB刷新脏页量可以超出innodb_io_capacity值。innodb_io_capacity_max表示在这种紧急情况下使用的I/O容量的上限,以便I/O中的尖峰消耗不到服务器的所有容量。
innodb_flushing_avg_loops:默认30,定义了innodb保留先前计算的刷新状态快照的迭代次数, 它控制了自适应刷新对此前负载更改的响应速度。为innodb_flushing_avg_loops设置高值意味着innodb保留以前计算的快照的时间更长,因此自适应刷新的响应速度更慢,高值还可以减少前台和后台工作之间的正面反馈。但是,在设置高值时,确保innodb重做日志利用率不达到75% (异步刷新开始时的硬编码限制) 和innodb_max_dirty_pages_pct设置将脏页的数量保持为适合于工作负荷的级别是很重要的。
上面提到的大多数选项最适用于长时间运行写入繁重工作负载的服务器。
九、保存和恢复缓冲池状态
这是MySQL对Buffer Pool做的一个重要特性,当MySQL重启后能够快速把Buffer Pool恢复到关闭前的状态,也称之为快速预热Buffer Pool。
1. 在关闭时保存缓冲池状态并在启动时恢复缓冲池状态
可以配置在MySQL关闭之前,保存InnoDB当前的缓冲池的状态,以避免在服务器重新启动后,还要经历一个预热的暖机时间。通过innodb_buffer_pool_dump_at_shutdown(服务器关闭前设置)来设置,当设置这个参数以后MySQL就会在机器关闭时保存一份Buffer Pool中LRU链表信息到磁盘上(主要保存SPACE ID和PAGE ID)。LUR链表信息保存文件默认在数据目录下,名为”ib_buffer_pool”,此文件中记录了SPACE ID和PAGE ID(如果没有此文件你可以手动触发一下保存缓冲池状态信息),可以使用innodb_buffer_pool_filename参数来修改文件名和位置。
|
1 2 3 4 5 6 |
$ more /var/lib/mysql/ib_buffer_pool 0,7 0,1 0,3 0,2 .... |
当启动MySQL服务器时要恢复服务器缓冲池状态,请在启动服务器时开启innodb_buffer_pool_load_at_startup参数。个人认为这个值还是需要配置一下的,MySQL 5.7.6版本之前这两个值默认是关闭的,但从MySQL 5.7.7版本开始这两个值就默认为开启状态了。开启后,MySQL启动时就会根据“ib_buffer_pool”文件记录的SPACE ID和PAGE ID把这些数据页从磁盘重新读取到Buffer Pool当中的,这会花费一些时间,并且恢复时新的DML操作是不能够进行操作的。
正常关机和开机都会在error日志文件中看到dump和load相关信息,并且会有相关的加载时间等信息,可以自己试试看。
2. 配置缓冲池页面保存的百分比
在进行导出Buffer Pool数据之前,可以通过设置参数innodb_buffer_pool_dump_pct来决定导出LRU链表前百分之多少的页。MySQL 5.7.6版本之前的默认值是100,导出全部。从MySQL 5.7.7版本之后默认调整为25%了,可以动态设置此参数:
|
1 |
mysql> SET GLOBAL innodb_buffer_pool_dump_pct = 40; |
不管是手动dump,还是关机自动dump,这个参数都是有作用的。你可以试试连续多次dump后,“ib_buffer_pool”文件中的行数会越来越少的。
3. 在线保存和恢复缓冲池状态
要在运行MySQL服务器时保存缓冲池的状态,请发出以下语句:
|
1 |
mysql> SET GLOBAL innodb_buffer_pool_dump_now=ON; |
要在MySQL运行时恢复缓冲池状态,请发出以下语句:
|
1 |
mysql> SET GLOBAL innodb_buffer_pool_load_now = ON; |
如果要终止buffer pool加载,可以指定运行:
|
1 |
mysql> SET GLOBAL innodb_buffer_pool_load_abort=ON; |
4. 显示缓冲池保存和加载进度
要想显示将缓冲池状态保存到磁盘时的进度,请发出以下语句:
|
1 2 3 4 5 6 7 |
mysql> SHOW STATUS LIKE 'Innodb_buffer_pool_dump_status'; +--------------------------------+------------------------------------+ | Variable_name | Value | +--------------------------------+------------------------------------+ | Innodb_buffer_pool_dump_status | Dumping of buffer pool not started | +--------------------------------+------------------------------------+ 1 row in set (0.03 sec) |
要想显示加载缓冲池时的进度,请发出以下语句:
|
1 2 3 4 5 6 7 |
mysql> SHOW STATUS LIKE 'Innodb_buffer_pool_load_status'; +--------------------------------+--------------------------------------------------+ | Variable_name | Value | +--------------------------------+--------------------------------------------------+ | Innodb_buffer_pool_load_status | Buffer pool(s) load completed at 170428 16:13:21 | +--------------------------------+--------------------------------------------------+ 1 row in set (0.00 sec) |
而且我们可以通过innodb的performance schema监控Buffer Pool的LOAD状态,打开或者关闭stage/innodb/buffer pool load。
|
1 |
mysql> UPDATE performance_schema.setup_instruments SET ENABLED = 'YES' WHERE NAME LIKE 'stage/innodb/buffer%'; |
启动events_stages_current,events_stages_history,events_stages_history_long表监控。
|
1 |
mysql> UPDATE performance_schema.setup_consumers SET ENABLED = 'YES' WHERE NAME LIKE '%stages%'; |
通过启用保存当前的缓冲池状态来获取最近的buffer pool状态。
|
1 2 3 4 5 |
mysql> SHOW STATUS LIKE 'Innodb_buffer_pool_dump_status'\G *************************** 1. row *************************** Variable_name: Innodb_buffer_pool_dump_status Value: Buffer pool(s) dump completed at 170525 18:41:06 1 row in set (0.01 sec) |
通过启用恢复当前的缓冲池状态来获取最近加载到buffer pool状态。
|
1 2 |
mysql> SET GLOBAL innodb_buffer_pool_load_now=ON; Query OK, 0 rows affected (0.00 sec) |
通过查询性能模式events_stages_current表来检查缓冲池加载操作的当前状态,该WORK_COMPLETED列显示加载的缓冲池页数,该WORK_ESTIMATED列提供剩余工作的估计,以页为单位。
|
1 2 3 4 5 6 |
mysql> SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM performance_schema.events_stages_current; +-------------------------------+----------------+----------------+ | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | +-------------------------------+----------------+----------------+ | stage/innodb/buffer pool load | 5353 | 7167 | +-------------------------------+----------------+----------------+ |
如果缓冲池加载操作已经完成,该表将返回一个空集合。在这种情况下,你可以检查events_stages_history表以查看已完成事件的数据。例如:
|
1 2 3 4 5 6 |
mysql> SELECT EVENT_NAME, WORK_COMPLETED, WORK_ESTIMATED FROM performance_schema.events_stages_history; +-------------------------------+----------------+----------------+ | EVENT_NAME | WORK_COMPLETED | WORK_ESTIMATED | +-------------------------------+----------------+----------------+ | stage/innodb/buffer pool load | 7167 | 7167 | +-------------------------------+----------------+----------------+ |
注意:在使用innodb_buffer_pool_load_at_startup启动时加载缓冲池时,还可以使用performance scheme来监视缓冲池负载进度,在这种情况下,需要开启stage/innodb/buffer pool load。有关更多信息,看:Section 25.3, “Performance Schema Startup Configuration”
需要留意的一点是如果是压缩表的话,在读取到buffer pool的时候还是会保持压缩的格式,直到被读取的时候才会调用解压程序进行解压。
MySQL 5.7.18版本相关参数的默认值如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# MySQL 5.7.18; mysql> show global variables like '%innodb_buffer_pool%'; +-------------------------------------+----------------+ | Variable_name | Value | +-------------------------------------+----------------+ | innodb_buffer_pool_chunk_size | 134217728 | | innodb_buffer_pool_dump_at_shutdown | ON | | innodb_buffer_pool_dump_now | OFF | | innodb_buffer_pool_dump_pct | 25 | | innodb_buffer_pool_filename | ib_buffer_pool | | innodb_buffer_pool_instances | 1 | | innodb_buffer_pool_load_abort | OFF | | innodb_buffer_pool_load_at_startup | ON | | innodb_buffer_pool_load_now | OFF | | innodb_buffer_pool_size | 134217728 | +-------------------------------------+----------------+ 10 rows in set (0.00 sec) |
<参考>
http://ourmysql.com/archives/852
http://mysql.taobao.org/monthly/2017/11/05/
https://mp.weixin.qq.com/s/Yjdh5H1s7tI1Bp7NPCXpqg
https://mp.weixin.qq.com/s/JsAcAhKg0D9KCuRdusb-HQ
https://dev.mysql.com/doc/refman/5.7/en/innodb-performance-buffer-pool.html