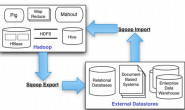
Sqoop简介
Sqoop是一个用于Hadoop和关系型数据库或主机之间的数据传输工具。它可以将数据从关系型数据库import到HDFS,也可以从HDFS export到关系型数据库,通过Hadoop的MapReduce实现。
最近在研究数据采集相关的知识,需要用到Sqoop把关系型数据库的数据导入到Hive里。刚开始就使用了Sqoop 1.99版本,用着发现太难用了,且很多问题,针对Sqoop 1.99还写了几篇博客。没办法又改回到了1.4.6版本,根据Sqoop官网说法,Sqoop2目前还未开发完,不建议在生产环境使用。
Sqoop安装配置
关于二进制包去Apache官网下载即可。
|
1 2 3 |
$ wget http://mirrors.hust.edu.cn/apache/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha $ tar xvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha -C /usr/local $ ln -sv /usr/local/sqoop-1.4.6.bin__hadoop-2.0.4-alpha /usr/local/sqoop |
设置环境变量
|
1 2 3 |
$ cat /etc/profile.d/sqoop.sh export SQOOP_HOME=/usr/local/sqoop export PATH=$PATH:$SQOOP_HOME/bin |
设置sqoop-env.sh文件
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
$ cat /usr/local/sqoop-146/conf/sqoop-env.sh export HADOOP_HOME=/usr/local/hadoop #Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/usr/local/hadoop #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/usr/local/hadoop #set the path to where bin/hbase is available export HBASE_HOME=/usr/local/hbase #Set the path to where bin/hive is available export HIVE_HOME=/usr/local/hive #Set the path for where zookeper config dir is export ZOOCFGDIR=/usr/local/zookeeper export HCAT_HOME=${HIVE_HOME}/hcatalog/ export PATH=$HCAT_HOME/bin:$PATH |
查看帮助命令
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
[hadoop@hadoop-nn ~]$ sqoop help usage: sqoop COMMAND [ARGS] Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information See 'sqoop help COMMAND' for information on a specific command. |
命令含义解释:
list-databases:列出所有数据库。
|
1 |
$ sqoop list-databases --connect jdbc:mysql://10.10.0.245:3306 --username root --password 123456 2> /dev/null |
list-tables:列出库中所有表。
|
1 |
$ sqoop list-tables --connect jdbc:mysql://10.10.0.245:3306/sbtest --username root --password 123456 2> /dev/null |
export:从HDFS导出到关系型数据库,目标table必须存在,可分为insert和update模式。
metastore:指定metadata仓库,可在配置文件中设置。
merge:合并两个数据集,一个数据集的记录应该重新旧数据集的条目。
codegen:将数据集封装成Java类。
create-hive-table:Sqoop单独提供了针对Hive的命令,可以代替sqoop import --hive-import, 其他参数一样。
eval:执行SQL语句,结果会打印在控制台,可以用来校验下import的查询条件是否正确。
import:从关系型数据库导入到HDFS。
sqoop-import-mainframe:直接import主机,这个命令过于暴力,和import-all-tables差别不大,等有需要在研究研究吧。
job:Sqoop可以将import任务保存为job,可以理解为起了个别名,这样方便的Sqoop任务的管理。
import-all-tables:可以整库的import,但有以为下限制条件:
- 每个表都必须有一个单列主键,或者指定
--autoreset-to-one-mapper参数。 - 每个表只能import全部列,即不可指定列import。
- 不能使用非默认的分隔符,不能指定where从句。
具体使用方法参见官方文档, 这里我们主要介绍下import命令的注意点。
Import和export参数解释
Common arguments:
–connect <jdbc-uri> :连接RDBMS的jdbc连接字符串,例如:–connect jdbc:mysql:// MYSQL_SERVER:PORT/DBNAME。
–connection-manager <class-name> :
–hadoop-home <hdir> :
–username <username> :连接RDBMS所使用的用户名。
–password <password> :连接RDBMS所使用的密码,明文。
–password-file <password-file> :使用文件存储密码。
-p :交互式连接RDBMS的密码。
Import control arguments:
–append :追加数据到HDFS已经存在的文件中。
–as-sequencefile :import序列化的文件。
–as-textfile :import文本文件 ,默认。
–columns <col,col,col…> :指定列import,逗号分隔,比如:–columns “id,name”。
–delete-target-dir :删除存在的import目标目录。
–direct :直连模式,速度更快(HBase不支持)
–split-by :分割导入任务所使用的字段,需要明确指定,推荐使用主键。
–inline-lob-limit < n > :设置内联的BLOB对象的大小。
–fetch-size <n> :一次从数据库读取n个实例,即n条数据。
-e,–query <statement> :构建表达式<statement>执行。
–target-dir <d> :指定HDFS目标存储目录。
–warehouse-dir <d> :可以指定为-warehouse-dir/user/hive/warehouse/即导入数据的存放路径,如果该路径不存在,会首先创建。
–table <table-name> :将要导入到hive的表。
–where <where clause> :指定where从句,如果有双引号,注意转义 \$CONDITIONS,不能用or,子查询,join。
-z,–compress :开启压缩。
–null-string <null-string> :string列为空指定为此值。
–null-non-string <null-string> :非string列为空指定为此值,-null这两个参数are optional, 如果不设置,会指定为”null”。
–autoreset-to-one-mapper :如果没有主键和split-by用one mapper import (split-by和此选项不共存)。
-m,–num-mappers <n> :建立n个并发执行import,默认4个线程。
Incremental import arguments:
–check-column <column> :Source column to check for incremental change
–incremental <import-type> :Define an incremental import of type ‘append’ or ‘lastmodified’
–last-value <value> :Last imported value in the incremental check column
Hive arguments:
–create-hive-table :自动推断表字段类型直接建表,hive-overwrite功能可以替代掉了,但Hive里此表不能存在,不然操作会报错。
–hive-database <database-name> :指定要把HDFS数据导入到哪个Hive库。
–hive-table <table-name> :设置到Hive当中的表名。
–hive-delims-replacement <arg> :导入到hive时用自定义的字符替换掉\n, \r, and \01。
–hive-drop-import-delims :导入到hive时删除字段中\n, \r,\t and \01等符号;避免字段中有空格导致导入数据被截断。
–hive-home <dir> :指定Hive的存储目录。
–hive-import :将HDFS数据导入到Hive中,会自动创建Hive表,使用hive的默认分隔符。
–hive-overwrite :对Hive表进行覆盖操作(需配合--hive-import使用,如果Hive里没有表会先创建之),不然就是追加数据。
–hive-partition-key <partition-key> :hive分区的key。
–hive-partition-value <partition-value> :hive分区的值。
–map-column-hive <arg> :类型匹配,SQL类型对应到hive类型。
HBase arguments:
–column-family < family > :把内容导入到hbase当中,默认是用主键作为split列。
–hbase-create-table :创建Hbase表。
–hbase-row-key < col > :指定字段作为row key ,如果输入表包含复合主键,用逗号分隔。
–hbase-table < table-name > :指定hbase表。
HCatalog arguments:
HCatalog提供表和存储管理服务,使不同的Hadoop数据处理工具如:Pig,MapReduce,Hive更容易读取和写入数据网格。
看文档比较复杂,暂时用不到,等以后需要的时候再去研究吧o(╯□╰)o
Accumulo arguments:
也没有研究,直接关闭了。
Import使用测试
单表导入HDFS
|
1 2 3 4 5 6 7 8 |
$ sqoop import \ --connect jdbc:mysql://10.10.0.245:3306/sbtest \ --username root \ --password 123456 \ --table sbtest1 \ --delete-target-dir \ --target-dir /sqoop \ -m 4 |
会在HDFS目录下创建:
|
1 2 3 4 5 6 7 |
[hadoop@hadoop-nn ~]$ hdfs dfs -ls /sqoop Found 5 items -rw-r--r-- 2 hadoop supergroup 0 2017-06-22 04:38 /sqoop/_SUCCESS -rw-r--r-- 2 hadoop supergroup 48388895 2017-06-22 04:38 /sqoop/part-m-00000 -rw-r--r-- 2 hadoop supergroup 48500000 2017-06-22 04:38 /sqoop/part-m-00001 -rw-r--r-- 2 hadoop supergroup 48500000 2017-06-22 04:38 /sqoop/part-m-00002 -rw-r--r-- 2 hadoop supergroup 48500001 2017-06-22 04:38 /sqoop/part-m-00003 |
单表导入到Hive
Sqoop导数据到hive会先将数据导入到HDFS上,然后再将数据load到hive中,最后吧这个目录再删除掉。当这个目录存在的情况下,就会报错。使用target-dir来指定一个临时目录(如果执行成功会删除这个目录的)。
|
1 2 3 4 5 6 7 8 9 10 11 |
$ sqoop import \ --connect jdbc:mysql://10.10.0.245:3306/sbtest \ --username root \ --password 123456 \ --table sbtest1 \ --delete-target-dir \ --target-dir /sqoop \ --hive-database sbtest \ --hive-import \ --hive-overwrite \ -m 8 |
这里指定了Hive库,所以需要先进行Hive数据库创建。如果不指定库,默认在default库中存放。
|
1 |
hive> create database hive charset utf8; |
执行成功后,去看一下HDFS。
|
1 2 3 4 5 6 |
[hadoop@hadoop-nn ~]$ hdfs dfs -ls / Found 4 items drwxr-xr-x - hadoop supergroup 0 2017-06-19 01:43 /hbase drwxr-xr-x - hadoop supergroup 0 2017-06-18 11:26 /log drwx------ - hadoop supergroup 0 2017-06-22 05:01 /tmp drwx-wx-wx - hadoop supergroup 0 2017-06-22 05:01 /user |
没有Sqoop目录,用完已经删除了。
然后看Hive目录下,sbtest库中已经产生了对应的表:
|
1 2 3 |
[hadoop@hadoop-nn ~]$ hdfs dfs -ls /user/hive/warehouse/sbtest.db Found 1 items drwx-wx-wx - hadoop supergroup 0 2017-06-22 05:14 /user/hive/warehouse/sbtest.db/sbtest1 |
然后你可以执行Hive,统计看看数据对不对。
|
1 |
[hadoop@hadoop-nn ~]$ hive -e "select count(*) from sbtest.sbtest1;" |
但是当MySQL中表有结构变化时,再次执行这个命令,由于Hive中的表没有变化,可能会报错,或者少字段。我还没有找到如果Hive中存在就先删除的指令。
全库导入Hive
|
1 2 3 4 5 6 7 8 |
$ sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \ --connect jdbc:mysql://10.10.0.245:3306/sbtest \ --username root \ --password 123456 \ --hive-database sbtest \ --hive-import \ --hive-overwrite \ -m 4 |
删除库的命令:
|
1 |
hive> drop database if exists sbtest cascad |
整机导入脚本
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#!/bin/bash # host=10.10.0.245 port=3306 user="root" pass="123456" db=`mysql -h$host -P$port -u$user -p$pass -e "show databases;" | egrep -v "(information_schema|test|sys|mysql|performance_schema|Database)"` for i in $db;do hive -e "drop database if exists $i cascade;" &> /dev/null done for i in $db;do hive -e "create database if Not Exists ${i};" &> /dev/null sqoop import-all-tables -Dorg.apache.sqoop.splitter.allow_text_splitter=true \ --connect jdbc:mysql://$host:$port/$i \ --username $user \ --password $pass \ --hive-database $i \ --hive-import \ --hive-overwrite \ -m 10 &> /tmp/sqoop.txt done |
Sqoop使用手册:http://www.cnblogs.com/xiaodf/p/6030102.html#31