一、复制集工作原理
1. 数据复制原理
开启复制集后,主节点会在 local 库下生成一个集合叫 oplog.rs,这是一个有限集合,也就是大小是固定的。其中记录的是整个mongod实例一段时间内数据库的所有变更(插入/更新/删除)操作,当空间用完时新记录自动覆盖最老的记录。
复制集中的从节点就是通过读取主节点上面的 oplog 来实现数据同步的,MongoDB的oplog(操作日志)是一种特殊的封顶集合,滚动覆盖写入,固定大小。另外oplog的滚动覆盖写入方式有两种:一种是达到设定大小就开始覆盖写入;二是设定文档数,达到文档数就开始覆盖写入(不推荐使用)。
复制集工作方式如下图:
")
主节点跟应用程序之间的交互是通过Mongodb驱动进行的,Mongodb复制集有自动故障转移功能,那么应用程序是如何找到主节点呢?Mongodb提供了一个rs.isMaster()函数,这个函数可以识别主节点。默认应用程序读写都是在主节点上,默认情况下,读和写都只能在主节点上进行。但是主压力过大时就可以把读操作分离到从节点上从而提高读性能。
下面是MongoDB的驱动支持5种复制集读选项:
primary:默认模式,所有的读操作都在复制集的主节点进行的。
primaryPreferred:在大多数情况时,读操作在主节点上进行,但是如果主节点不可用了,读操作就会转移到从节点上执行。
secondary:所有的读操作都在复制集的从节点上执行。
secondaryPreferred:在大多数情况下,读操作都是在从节点上进行的,但是当从节点不可用了,读操作会转移到主节点上进行。
nearest:读操作会在复制集中网络延时最小的节点上进行,与节点类型无关。
但是除了primary 模式以外的复制集读选项都有可能返回非最新的数据,因为复制过程是异步的,从节点上应用操作可能会比主节点有所延后。如果我们不使用primary模式,请确保业务允许数据存在可能的不一致。
举个例子:
用客户端向主节点添加了 100 条记录,那么 oplog 中也会有这 100 条的 insert 记录。从节点通过获取主节点的 oplog,也执行这 100 条 oplog 记录。这样,从节点也就复制了主节点的数据,实现了同步。
需要说明的是:并不是从节点只能获取主节点的 oplog。为了提高复制的效率,复制集中所有节点之间会互相进行心跳检测(通过ping)。每个节点都可以从任何其他节点上获取oplog。还有,用一条语句批量删除 50 条记录,并不是在 oplog 中只记录一条数据,而是记录 50 条单条删除的记录。oplog中的每一条操作,无论是执行一次还是多次执行,对数据集的影响结果是一样的,i.e 每条oplog中的操作都是幂等的。
- 初始化同步
- 回滚后的数据追赶
- 分片的chunk迁移
2. 复制集写操作
")
如果启用复制集的话,在内存中会多一个OPLOG区域,是在节点之间进行同步的一个手段,它会把操作日志放到OPLOG中来,然后OPLOG会复制到从节点上。从节点接收并执行OPLOG中的操作日志来达到数据的同步操作。
1) 客户端的数据进来;
2) 数据操作写入到日志缓冲;
3) 数据写入到数据缓冲;
4) 把日志缓冲中的操作日志放到OPLOG中来;
5) 返回操作结果到客户端(异步);
6) 后台线程进行OPLOG复制到从节点,这个频率是非常高的,比日志刷盘频率还要高,从节点会一直监听主节点,OPLOG一有变化就会进行复制操作;
7) 后台线程进行日志缓冲中的数据刷盘,非常频繁(默认100)毫秒,也可自行设置(30-60)。
后台线程进行数据缓冲中的数据刷盘,默认是60秒。
3. Oplog的数据结构
|
1 2 3 4 5 6 7 8 9 10 11 |
ywnds:PRIMARY> db.oplog.rs.findOne() { "ts" : Timestamp(1453059127, 1), "h" : NumberLong("-6090285017139205124"), "v" : 2, "op" : "n", "ns" : "", "o" : { "msg" : "initiating set" } } |
ts:操作发生时的时间戳,这个时间戳包含两部分内容t和i,t是标准的时间戳(自1970年1月1日 00:00:00 GMT 以来的毫秒数)。而i是一个序号,目的是为了保证t与i组合出的Mongo时间戳ts可以唯一的确定一条操作记录。
h:此操作的独一无二的ID。
v:oplog的版本。
op:操作类型(insert、update、delete、db cmd、null),紧紧代表一个消息信息。
ns:操作所处的命名空间(db_name.coll_name)。
o:操作对应的文档,文档在更新前的状态(“msg” 表示信息)。
o2:仅update操作时有,更新操作的变更条件(只记录更改数据)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ "ts" : Timestamp(1481094522, 1), "t" : NumberLong(1), "h" : NumberLong("-7286476219427328778"), "v" : 2, "op" : "u", "ns" : "test.foo", "o2" : { "_id" : ObjectId("58466e872780d8f6f65951ad") }, "o" : { "_id" : ObjectId("58466e872780d8f6f65951ad"), "a" : 1000 } } |
PS:当你想查询最后一次数据库操作的oplog记录时,可以使用此语句db.oplog.rs.find().sort({$natural:-1}).limit(1).pretty()。
需要重点强调的是oplog只记录改变数据库状态的操作。比如,查询就不存储在oplog中。这是因为oplog只是作为从节点与主节点保持数据同步的机制。存储在oplog中的操作也不是完全和主节点的操作一模一样的,这些操作在存储之前先要做等幂变换,也就是说,这些操作可以在从服务器端多次执行,只要顺序是对的,就不会有问题。例如,使用“$inc”执行的增加更新操作,会被转换为“$set”操作。
4. Oplog大小及意义
当你第一次启动复制集中的节点时,MongoDB会用默认大小建立Oplog。这个默认大小取决于你的机器的操作系统。大多数情况下,默认的oplog大小是足够的。在 mongod 建立oplog之前,我们可以通过设置 oplogSizeMB 选项来设定其大小。但是,如果已经初始化过复制集,已经建立了Oplog了,我们需要通过修改Oplog大小中的方式来修改其大小。
OpLog的默认大小:
- 在64位Linux、Windows操作系统上为当前分区可用空间的5%,但最大不会超过50G。
- 在64位的OS X系统中,MongoDB默认分片183M大小给Oplog。
- 在32位的系统中,MongoDB分片48MB的空间给Oplog。
4.1 复制时间窗口
既然Oplog是一个封顶集合,那么Oplog的大小就会有一个复制时间窗口的问题。举个例子,如果Oplog是大小是可用空间的5%,且可以存储24小时内的操作,那么从节点就可以在停止复制24小时后仍能追赶上主节点,而不需要重新获取全部数据。如果说从节点在24小时后开始追赶数据,那么不好意思主节点的oplog已经滚动覆盖了,把从节点没有执行的那条语句给覆盖了。这个时候为了保证数据一致性就会终止复制。然而,大多数复制集中的操作没有那么频繁,oplog可以存放远不止上述的时间的操作记录。但是,再生产环境中尽可能把oplog设置大一些也不碍事。使用rs.printReplicationInfo()可以查看oplog大小以及预计窗口覆盖时间。
|
1 2 3 4 5 6 |
test:PRIMARY> rs.printReplicationInfo() configured oplog size: 1024MB <--集合大小 log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间 oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST) oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST) now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST) |
4.2 Oplog大小应随着实际使用压力而增加
如果我能够对我复制集的工作情况有一个很好地预估,如果可能会出现以下的情况,那么我们就可能需要创建一个比默认大小更大的oplog。相反的,如果我们的应用主要是读,而写操作很少,那么一个小一点的oplog就足够了。
下列情况我们可能需要更大的oplog。
4.2.1 同时更新大量的文档。
Oplog为了保证 幂等性 会将多项更新(multi-updates)转换为一条条单条的操作记录。这就会在数据没有那么多变动的情况下大量的占用oplog空间。
4.2.2 删除了与插入时相同大小的数据
如果我们删除了与我们插入时同样多的数据,数据库将不会在硬盘使用情况上有显著提升,但是oplog的增长情况会显著提升。
4.2.3 大量In-Place更新
如果我们会有大量的in-place更新,数据库会记录下大量的操作记录,但此时硬盘中数据量不会有所变化。
4.3 Oplog幂等性
Oplog有一个非常重要的特性——幂等性(idempotent)。即对一个数据集合,使用oplog中记录的操作重放时,无论被重放多少次,其结果会是一样的。举例来说,如果oplog中记录的是一个插入操作,并不会因为你重放了两次,数据库中就得到两条相同的记录。
5. Oplog的状态信息
我们可以通过 rs.printReplicationInfo() 来查看oplog的状态,包括大小、存储的操作的时间范围。关于oplog的更多信息可以参考Check the Size of the Oplog。
|
1 2 3 4 5 6 |
test:PRIMARY> rs.printReplicationInfo() configured oplog size: 1024MB <--集合大小 log length start to end: 423849secs (117.74hrs) <--预计窗口覆盖时间 oplog first event time: Wed Sep 09 2015 17:39:50 GMT+0800 (CST) oplog last event time: Mon Sep 14 2015 15:23:59 GMT+0800 (CST) now: Mon Sep 14 2015 16:37:30 GMT+0800 (CST) |
在各类异常情况下,从节点oplog的更新可能落后于主节点一些时间。在从节点上通过 db.getReplicationInfo() 和 db.getReplicationInfo 可以获得现在复制集的状态与,也可以知道是否有意外的复制延时。
|
1 2 3 4 5 6 7 8 9 10 |
test:SECONDARY> db.getReplicationInfo() { "logSizeMB" : 1024, "usedMB" : 168.06, "timeDiff" : 7623151, "timeDiffHours" : 2117.54, "tFirst" : "Fri Aug 19 2016 12:27:04 GMT+0800 (CST)", "tLast" : "Tue Nov 15 2016 17:59:35 GMT+0800 (CST)", "now" : "Tue Dec 06 2016 11:27:36 GMT+0800 (CST)" } |
二、组建集群过程
MongoDB添加从库比较简单,在安装从库之后,直接在主库执行rs.add()或者replSetReconfig命令即可添加,这两个命令其实在最终都调用replSetReconfig命令执行。大家有兴趣可以去翻阅MongoDB客户端JS代码。
然后我们来看副本集加一个新从库的大致步骤,如下图,右边的Secondary是我新加的从库。
")
通过上图我们可以看到一共有7个步骤,下面我们看看每一个步骤MongoDB都做了什么:
1、 主库收到添加从库命令。
2、 主库更新副本集配置并与新从库建立心跳机制。
3、 从库收到主库发送过来的心跳消息与主库建立心跳。
4、 其他从库收到主库发来的新版本副本集配置信息并更新自己的配置。
5、 其他从库与新从库建立心跳机制。
6、 新从库收到其他从库心跳信息并跟其他从库建立心跳机制。
7、 新加的节点将副本集配置信息更新到local.system.replset集合中,MongoDB会在一个循环中查询local.system.replset是否配置了replset 信息,一旦查到相关信息触发开启复制线程,然后判断是否需要全量复制,需要的话走全量复制,不需要走增量复制。
8、 最终同步建立完成。
注意:
副本集所有节点之前都有相互的心跳机制,每2秒一次,在MongoDB 3.2版本以后我们可以通过heartbeatIntervalMillis参数来控制心跳频率。
上述过程大家可以结合副本集节点状态来看(rs.status命令):
- STARTUP:在副本集每个节点启动的时候,mongod加载副本集配置信息,然后将状态转换为STARTUP2
- STARTUP2:加载配置之后决定是否需要做Initial Sync,需要则停留在STARTUP2状态,不需要则进入RECOVERING状态
- RECOVERING:处于不可对外提供读写的阶段,主要在Initial Sync之后追增量数据时候。
另外,如果该节点最新的oplog时间戳,比所有节点最旧的oplog时间戳还要小,该节点将找不到同步源,会一直处于RECOVERING而不能服务;反之,如果能找到同步源,则直接进入replication阶段,不断的应用新的oplog。因oplog太旧而处于RECOVERING的节点目前无法自动恢复,需人工介入处理(故设置合理的oplog大小非常重要),最简单的方式是发送resync命令,让该节点重新进行initial sync。
三、节点数据复制流程
Mongodb复制集里的Secondary会从Primary上同步数据,以保持副本集所有节点的数据保持一致,数据同步主要包含2个过程。
- initial sync
- replication(oplog sync)
上面我们知道添加一个从库的大致流程,那我们现在来看主从数据同步的具体细节。当从库加入到副本集的时候,会判断自己是需要Initial Syc(全量同步)还是增量同步。那是通过什么条件判断的呢?主要参考下面三个条件。
1. Secondary上oplog为空,比如新加入的空节点。
2. local.replset.minvalid集合里_initialSyncFlag标记被设置。当initial sync开始时,同步线程会设置该标记,当initial sync结束时清除该标记,故如果initial sync过程中途失败,节点重启后发现该标记被设置,就知道应该重新进行initial sync。
3. BackgroundSync::_initialSyncRequestedFlag被设置,当向节点发送resync命令时,该标记会被设置,此时会强制重新initial sync。
以上三个条件有一个条件满足就需要做全量同步。我们可以得出在从库最开始加入到副本集的时候,只能先进行Initial Sync,下面我们来看看Initial Sync的具体流程。
全量同步流程(Initial sync)
1. 寻找数据源
这里先说明一点,MongoDB默认是采取级联复制的架构,就是默认不一定选择主库作为自己的同步源,如果不想让其进行级联复制,可以通过chainingAllowed参数来进行控制。在级联复制的情况下,你也可以通过replSetSyncFrom命令来指定你想复制的同步源。所以这里说的同步源其实相对于从库来说就是它的主库。那么同步源的选取流程是怎样的呢?
MongoDB从库会在副本集其他节点通过以下条件筛选符合自己的同步源。
- 如果设置了chainingAllowed 为false,那么只能选取主库为同步源
- 找到与自己ping时间最小的并且数据比自己新的节点 (在副本集初始化的时候,或者新节点加入副本集的时候,新节点对副本集的其他节点至少ping两次)
- 该同步源与主库最新optime做对比,如果延迟主库超过30s,则不选择该同步源。
- 在第一次的过滤中,首先会淘汰比自己数据还旧的节点。如果第一次没有,那么第二次需要算上这些节点,防止最后没有节点可以做为同步源了。
- 最后确认该节点是否被禁止参与选举,如果是则跳过该节点。
通过上述筛选最后过滤出来的节点作为新的同步源。
其实MongoDB同步源在除了在Initial Sync和增量复制 的时候选定之后呢,并不是一直是稳定的,它可能在以下情况下进行变更同步源:
- ping不通自己的同步源
- 自己的同步源角色发生变化
- 自己的同步源与副本集任意一个节点延迟超过30s
2. 删除MongoDB中除local以外的所有数据库
3. 拉取主库存量数据
这里就到了Initial Sync的核心逻辑了,同步流程如下:
0. 在minValid集合中设置_initialSyncFlag标志(db.replset.minvalid.find()),告诉我们如果在这个过程中间出现死机则重新初始同步。
1. 获取同步源当前最新的oplog时间戳t0。
2. 从同步源克隆所有的集合数据。
3. 获取同步源最新的oplog时间戳t1。
4. 同步t0~t1所有的oplog。
5. 获取同步源最新的oplog时间戳t2。
6. 同步t1~t2所有的oplog。
7. 从同步源读取index信息,并建立索引(除了_id ,这个之前已经建立完成)。
8. 获取同步源最新的oplog时间戳t3。
9. 同步t2~t3所有的oplog。
10. 从minValid集合中清除_initialSyncFlag,initial sync结束。
注:本流程针对于MongoDB 3.4之前的版本,以上步骤直接翻译的MongoDB源码中的注释。
当完成了所有操作后,该节点将会变为正常的状态Secondary。
以上步骤在 MongoDB 3.4 Initial Sync 有如下改进:
- 在创建的集合的时候同时创建了索引(与主库一样),在MongoDB 3.4版本之前只创建
_id索引,其他索引等待数据copy完成之后进行创建。 - 在创建集合和拷贝数据的同时,也将oplog拷贝到本地local数据库中,等到数据拷贝完成之后,开始应用本地oplog数据。
- 新增由于网络问题导致Initial Sync失败重试机制。
- 在Initial Sync期间发现collection重命名了会重新开始Initial Sync。
上述4个新增特性提升了Initial Sync的效率并且提高了Initial Sync的可靠性,所以大家使用MongoDB最好使用最新版本MongoDB 3.4或者3.6,MongoDB 3.6更是有一些令人兴奋的特性,这里就不在此叙述了。全量同步完成之后,然后MongoDB会进入到增量同步的流程。
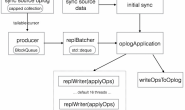
增量数据同步(sync oplog)
上面我们介绍了Initial Sync,就是已经把同步源的存量数据拿过来了,那主库后续写入的数据怎么同步过来呢?下面还是以图跟具体的步骤来给大家介绍:
- Sencondary初始化同步完成之后,开始增量复制,通过produce线程在Primary oplog.rs集合上建立cursor,并且实时请求获取数据。
- Primary返回oplog数据给Secondary。
- Sencondary读取到Primary发送过来的oplog,将其写入到队列中。
- Sencondary的同步线程会通过tryPopAndWaitForMore方法一直消费队列,当每次达到一定的条件之后,条件如下:
- 总数据大于100MB
- 已经取到部分数据但没到100MB,但是目前队列没数据了,这个时候会阻塞等待一秒,如果还没有数据则本次取数据完成。
上述两个条件满足一个之后,就会将数据给prefetchOps方法处理,prefetchOps方法主要将数据以namespace进行分组,划分到多个线程里,保证同一个namespace的所有操作都由一个线程来replay,以保证统一namespace的操作时序跟primary上保持一致。如果采用的WiredTiger引擎,那这里是以Docment ID进行切分。
5. 最终将划分好的数据以多线程的方式批量写入到数据库中(在从库批量写入数据的时候MongoDB会阻塞所有的读)。
6. 然后再将Queue中的Oplog数据写入到Sencondary中的oplog.rs集合中。