一、MongoDB副本集数据同步方式
- intial sync,可以理解为全量同步。
- replication,追同步源的oplog,可以理解为增量同步。
下面会详细介绍MongoDB数据同步的实现原理。
initial sync
Secondary节点当出现如下状况时,需要先进行全量同步。
- oplog为空。
- local.replset.minvalid集合里_initialSyncFlag字段设置为true。
- 内存标记initialSyncRequested设置为true。
这3个场景分别对应
- 新节点加入,无任何oplog,此时需先进性initial sync。
- initial sync开始时,会主动将_initialSyncFlag字段设置为true,正常结束后再设置为false;如果节点重启时,发现_initialSyncFlag为true,说明上次全量同步中途失败了,此时应该重新进行initial sync。
- 当用户发送resync命令时,initialSyncRequested会设置为true,此时会重新开始一次initial sync。
intial sync流程
- 全量同步开始,设置minvalid集合的_initialSyncFlag。
- 获取同步源上最新oplog时间戳为t1。
- 全量同步集合数据 (耗时)。
- 获取同步源上最新oplog时间戳为t2。
- 重放[t1, t2]范围内的所有oplog。
- 获取同步源上最新oplog时间戳为t3。
- 重放[t2, t3]范围内所有的oplog。
- 建立集合所有索引 (耗时)。
- 获取同步源上最新oplog时间戳为t4。
- 重放[t3, t4]范围内所有的oplog。
- 全量同步结束,清除minvalid集合的_initialSyncFlag。
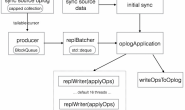
Replication
initial sync结束后,接下来Secondary就会『不断拉取主上新产生的oplog并重放』,这个过程在Secondary同步慢问题分析也介绍过,这里从另一个角度再分析下。

- producer thread,这个线程不断的从同步源上拉取oplog,并加入到一个BlockQueue的队列里保存着。
- replBatcher thread,这个线程负责逐个从producer thread的队列里取出oplog,并放到自己维护的队列里。
- sync线程将replBatcher thread的队列分发到默认16个replWriter线程,由replWriter thread来最终重放每条oplog。
问题来了,为什么一个简单的『拉取oplog并重放』的动作要搞得这么复杂?
性能考虑,拉取oplog是单线程进行,如果把重放也放到拉取的线程里,同步势必会很慢;所以设计上producer thread只干一件事。
为什么不将拉取的oplog直接分发给replWriter thread,而要多一个replBatcher线程来中转?
oplog重放时,要保持顺序性,而且遇到createCollection、dropCollection等DDL命令时,这些命令与其他的增删改查命令是不能并行执行的,而这些控制就是由replBatcher来完成的。
注意事项
- initial sync单线程复制数据,效率比较低,生产环境应该尽量避免initial sync出现,需合理配置oplog,按默认『5%的可用磁盘空间』来配置oplog在绝大部分场景下都能满足需求,特殊的case(case1, case2)可根据实际情况设置更大的oplog。
- 新加入节点时,可以通过物理复制的方式来避免initial sync,将Primary上的dbpath拷贝到新的节点,直接启动,这样效率更高。
- 当Secondary上需要的oplog在同步源上已经滚掉时,Secondary的同步将无法正常进行,会进入RECOVERING的状态,需向Secondary主动发送resyc命令重新同步。3.2版本目前有个bug,可能导致resync不能正常工作,必须强制(kill -9)重启节点,详情参考SERVER-24773。
- 生产环境,最好通过db.printSlaveReplicationInfo()来监控主备同步滞后的情况,当Secondary落后太多时,要及时调查清楚原因。
- 当Secondary同步滞后是因为主上并发写入太高导致,(db.serverStatus().metrics.repl.buffer.sizeBytes持续接近db.serverStatus().metrics.repl.buffer.maxSizeBytes),可通过调整Secondary上replWriter并发线程数来提升。
二、MongoDB 3.4复制集全量同步改进
MongoDB 3.2版本复制集同步的过程参考上面,在MongoDB 3.4版本里MongoDB对复制集同步的全量同步阶段做了2个改进:
- 在拷贝数据的时候同时建立所有的索引,在之前的版本里,拷贝数据时会先建立_id索引,其余的索引在数据拷贝完之后集中建立
- 在拷贝数据的同时,会把同步源上新产生的oplog拉取到本地local数据库的临时集合存储着,等数据全量拷贝完,直接读取本地临时集合的oplog来应用,提升了追增量的效率,同时也避免了同步源上oplog不足导致无法同步的问题。

上图描述了这2个改进的效果,实测了『10GB的数据,包含64个集合,每个集合包含2个索引字段,文档平均1KB,3.4版本的全量同步性能约有20%的提升,如果数据集很大,并且在同步的过程中有写入,提升的效果会更明显,并且彻底解决了因同步源oplog不足而导致进入RECOVERING状态无法同步的问题。
<原文>
https://yq.aliyun.com/articles/57755?spm=5176.8091938.0.0.Opu19P