在上一章介绍了MongoDB的架构,复制集的架构直接影响着故障切换时的结果。为了能够有效的故障切换,请确保至少有一个节点能够顺利升职为主节点。保证在拥有核心业务系统的数据中心中拥有复制集中多数节点。让多数能够参与投票的节点或是所有可以成为主节点的节点在这个数据中心中。但是,如果节点间网络不通将会让其无法参与并成为多数节点。
如果你有了解一些常用的高可用软件,那么就会很清楚高可用中的选举机制了。我们先来看看复制集中选举的机制,了解几个概念。
一、大多数原则
1. 什么是大多数原则?
当前复制集中,存活节点的数量必须大于节点总数的1/2,这样才能触发选举,否则当从节点挂掉时主节点会降级为从节点;当主节点挂掉时从节点也不会升为主节点。
2. 怎么样才算大多数原则?
我们可以看下面这个图。
")
由于MongoDB的大多数原则,当复制集节点为3个时,主节点允许发生故障且剩余两个节点由于满足大多数原则所以会自动选出一台新的主节点。如果新选出来的主节点又发送故障那么不好意思此时最后一个从节点并不会成为主节点。
当复制集节点为4个时,主节点允许发送故障且剩余三个节点由于满足大多数原则所以会自动选出一台新的主节点。如果新选出来的主节点又发送故障那么不好意思此时剩余两个节点由于不满足大多数原则所以此复制集就不会有主节点了。
PS:由上述两个实例的说明,可以看出当复制集中的节点数位相邻的奇数和偶尔时,服务器的故障利用率则是相同的。所以当有偶数个节点时,此时可以做一个投票节点(此节点不暂用资源所以可以在其他正在提供服务的机器上运行)
3. 为什么会有大多数原则?
对于这个问题,初学者一般都持有疑问,感觉这个设计是个什么鬼?复制集是我们管理的,为什么不可以让管理员来设置谁做主,谁做从,然后当主节点挂掉之后允许那个从节点去接替主节点的工作。确实这个方法在有些高可用软件中就是这么指定的,如Linux中的keepalived、还有如CISCO的HSRP机制都是这么规定的。而到了Mongodb中就变成了选举管理员不可控。我们来看这个一种情况,如下图。
")
上图共有7个节点,DC1有4个节点并且主节点在DC1,而DC2有三个节点都是从节点。由于在两个机房之间的网络通信有很多不确定性,并且复制集节点之间主要靠心跳信息来确认对方是否存活是否重新选举,默认心跳信息从节点2秒传送一次给主节点,如果在10秒内对方没有回应那么就认为主节点故障从而触发选举。那么问题来了,比如说现在的7个节点的复制集已经稳定了,当网络出现大延迟的时候,DC1跟DC2之间已经无法正常传送心跳信息了,此时会发生什么情况?
DC1由于有一个主节点了,所以它的一主三从不会发生变化,但是DC2由于探测不到DC1的主节点从而三个从节点触发选举,会在三个节点中选出一个主节点来,此时一个复制集中出现了两个主节点就会导致数据不一致性。当MongoDB使用了大多数原则时当两个机房之间在遇到网络延迟时就不会发生出现两个主节点的情况了。当DC1探测不到DC2时,DC1由于有一个主节点了,所以它的一主三从不会发生变化。而DC2中的三台从节点由于不满足大多数原则(存活主机小于总主机数的1/2)所以不会产生选举,所以三个节点不会有是变化。看完分析之后不知道你明白了没有。
二、选举触发条件
- 新初始化一套副本集
- 从库不能连接到主库(默认超过10s,可通过heartbeatTimeoutSecs参数控制),从库发起选举
- 主库主动放弃primary角色,比如主动执行rs.stepdown命令,主库与大部分节点都无法通信等
三、影响选举的因素
1. 复制集心跳检测
Mongodb复制集成员之间的联系跟所有高可用所用的机制相同,那就是“心跳监测”机制,默认从节点会2秒一次地向主节点发出心跳监测请求,如果对方在10秒之内没有回应的话,就会认为节点故障。
当主节点不可达时,复制集会做一个判断,其他成员是否对主节点也不可达。如果都不可达那么复制集就会产生新的选举争取选出一台主节点从新为应用程序提供服务。
其他节点不可达时,
2. 成员优先级
一个复制集稳定的初选后,选举算法将作出努力尝试把具有最高优先级的可用从节点呼叫出出来选举。比如,如果在复制集中主节点的优先级大于默认值1,那么当主节点宕机重新恢复后成为从节点但由于优先级大于现有的主节点从而会重新取得主节点状态。当priority为0时表示永远没有资格成为主节点,且priority的值为0也是设置隐藏节点及延迟节点的前提条件。
3. 网络隔离
网络隔离影响了选举中多数选票的结构,如果主节点不可用了,且每个相互隔离的网络中都没有多数选票的出现,那么复制集将不会选举出新的主节点。复制集将变为只读的。为了避免这种情况的出现,我们需要将多数节点置于主数据中心,少数节点放于其他数据中心。
4. Replication Election Protocol
MongoDB 3.2新功能,MongoDB版本1的复制协议减少复制集切换时间和加速同时初选的检测。新的复制集默认情况下使用版本1,旧的MongoDB使用版本0是以前版本的协议。
四、选举的过程
复制集高可用选举过程大概有四个阶段,下图介绍了复制集选举的过程:
")
第一阶段:心跳检测
前面也说过,心跳检测是高可用的一个必要技术手段,心跳检测就是让每个成员通过心跳请求了解到当前集群中其他节点的状态。比如当前集群中谁是主节点,当前集群中存活的数量是否满足1/2原则等。
MongoDB副本集所有节点都是相互保持心跳的,然后心跳频率默认是2秒一次,也可以通过heartbeatIntervalMillis来进行控制。在新节点加入进来的时候,副本集中所有的节点需要与新节点建立心跳,那心跳信息具体是什么内容呢?
具体在MongoDB日志中表现如下:
|
1 |
command admin.$cmd command: replSetHeartbeat { replSetHeartbeat: "shard1", v: 21, pv: 1, checkEmpty: false, from: "10.13.32.244:40011", fromId: 3 } ntoreturn:1 keyUpdates:0 |
那副本集所有节点默认都是每2秒给其他剩余的节点发送上述信息,在其他节点收到信息后会调用ReplSetCommand命令来处理心跳信息,处理完成会返回当前节点信息,比如是否可以参与选举,oplog等信息。
第二阶段:维护主节点备选列表
什么是主节点备选列表,也就是说当需要进行选举的时候,选举出来一个新的主节点。那么谁能够有资格被选举成新的主节点呢?这个主节点选举也算是非常复杂的了,要经过一系列复杂的判断之后才能够进入主节点备选列表,下图详解介绍了一个节点进入主节点备选列表需要判断哪些条件?
")
接下来就要进入主节点检测环节
")
注意,这里说的是主节点备选列表,还不是被选为主节点。
第三阶段:选举准备
在选举准备阶段,又需要一系列判断,可以说是通过九九八十一难才能允许别人向自己投票。
")
当一个在主节点列表中的节点自身能够满足上述的几个条件后,就开始调用自选方法,选举自己成为新的主节点,但真正允许其他节点向自己投票它又需要经过下列一些自我检测才能最后敲定允许其他节点投票自己。如下图:
")
第四阶段:投票
最后就是投票了,在经历过投票之后就可以选出一个新的主节点了,如下图:
")
在最后一步投票结束后,参与选举的节点首先会进行检查自己是否收到反对票。什么时候会出现反对票呢?
第一就是自己的版本比其他数据库要低时会收到反对票;
第二就是当前复制集中已经选举出了一个主节点时会收到反对票;
第三在参与选举过程中有其他节点priority比它高时会收到反对票;
一旦收到反对票,此节点就会减10000票,投票可以通过vote设定一个节点可以投的票数,但默认都是1票。基本上就是一票否决制的,如果收到反对票就需要等待一段时间了。
然后检查是否有相同票数的,如果有相同票数的就需要重新选举了,重新来过。这样就是为什么前面多次提到MongoDB复制集的节点最好是基数个而不是偶数个了,就是为了避免相同票数的出现从而导致重新投票。
如果集群中没有相同票数的,接着还要检查自己的票数是否过半,如果过半就可以被选为主节点了。
终于完了,也是艰难啊,其实MongoDB在真正实现选举的机制比上面说的要麻烦的多。
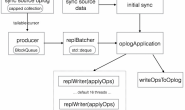
五、Rollback
我们知道在发生切换的时候是有可能造成数据丢失的,主要是因为主库宕机,但是新写入的数据还没有来得及同步到从库中,这个时候就会发生数据丢失的情况。
那针对这种情况,MongoDB增加了回滚的机制。在主库恢复后重新加入到复制集中,这个时候老主库会与同步源对比oplog信息,这时候分为以下两种情况:
- 在同步源中没有找到比老主库新的oplog信息。
- 同步源最新一条oplog信息跟老主库的optime和oplog的hash内容不同。
针对上述两种情况MongoDB会进行回滚,回滚的过程就是逆向对比oplog的信息,直到在老主库和同步源中找到对应的oplog,然后将这期间的oplog全部记录到rollback目录里的文件中,如果但是出现以下情况会终止回滚:
- 对比老主库的optime和同步源的optime,如果超过了30分钟,那么放弃回滚。
- 在回滚的过程中,如果发现单条oplog超过512M,则放弃回滚。
- 如果有dropDatabase操作,则放弃回滚。
- 最终生成的回滚记录超过300M,也会放弃回滚。
上述我们已经知道了MongoDB的回滚原理,但是我们在生产环境中怎么避免回滚操作呢,因为毕竟回滚操作很麻烦,而且针对有时序性的业务逻辑也是不可接受的。那MongoDB也提供了对应的方案,就是WriteConcern,这里就不细说了,有兴趣的朋友可以仔细了解。其实这也是在CAP中做出一个选择。