一、MongoDB 部署模式
MongoDB 的部署模式有三种,如下图所示。
机制")
第一种是单机模式(开发测试),第二种是高可用复制集,第三种是可扩展分片集群。知道了 MongoDB 几种常用的部署模式之后,接下来我们看看每种部署模式的写操作过程。
MongoDB 单点写操作
机制")
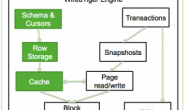
从上图可以看出,其中 primary 是 MongoDB 的一个实例,里面有两个内存区域,一个是 Data Buffer(数据缓冲)、一个是 Journal Buffer(日志缓冲)。这两个内存区域分别对应物理文件 Data File 和 Journal File。
当数据写入进来时,就会出现如下执行顺序:
机制")
1) 客户端的数据进来;
2) 数据操作写入到日志缓冲;
3) 数据写入到数据缓冲;
4) 返回操作结果到客户端(异步);
5) 后台线程进行日志缓冲中的数据刷盘,非常频繁(默认 100)毫秒,也可自行设置(30-60);
6) 后台线程进行数据缓冲中的数据刷盘,默认是 60 秒;
MongoDB 复制集写操作
机制")
复制集也是 MongoDB 最常见的一种部署模式,如果启用复制集的话,在内存中会多一个 OPLOG 区域,是在节点之间进行同步的一个手段,它会把操作日志放到 OPLOG 中来,然后 OPLOG 会复制到从节点上。从节点接收并执行 OPLOG 中的操作日志来达到数据的同步操作。
1) 客户端的数据进来;
2) 数据操作写入到日志缓冲;
3) 数据写入到数据缓冲;
4) 把日志缓冲中的操作日志放到 OPLOG 中来;
5) 返回操作结果到客户端(异步);
6) 后台线程进行 OPLOG 复制到从节点,这个频率是非常高的,比日志刷盘频率还要高,从节点会一直监听主节点,OPLOG 一有变化就会进行复制操作;
7) 后台线程进行日志缓冲中的数据刷盘,非常频繁(默认 100)毫秒,也可自行设置(30-60);
8) 后台线程进行数据缓冲中的数据刷盘,默认是 60 秒;
恢复日志 Journal 的作用
1) 用于系统宕机时恢复内存数据(就像 MySQL 的 redo 日志)
2) 默认为异步刷盘
3) 刷盘间隔,MMAP 引擎为 30-100ms,WiredTiger 为 100MB or checkpoint
4) 可使用 j:1 来强制同步刷盘
二、Write concern(写关注机制)
NOTE:
对于多文档事务,设置 Write concern 是在事务级别的,而不是一个独立的操作级别。没有明确设定在一个事务中个人写操作写入关注。
Write concern 可以包括以下字段:
|
1 |
{ w: <value>, j: <boolean>, wtimeout: <number> } |
w 选项请求确认(request acknowledgment)写入操作已经传播到指定数量的 mongod 实例,也就是写入操作的回执行为。或 mongod 的实例与指定的标签。
j 个选项,要求确认写操作的日志(journal)已被写入到磁盘上。
wtimeout 选项来指定一个时间限制,以防止无限期阻塞写操作。
w 选项
使用 w 选项,以下write concerns 的 w: <value> 是可用的:
| Value | Description |
|---|---|
|
请求确认该写操作传播到的 mongod 实例的指定数量。比如:
当 w 大于 1 时,请求确认需要来自复制集 primary 节点和多个 secondaries 节点满足指定的 write concern。例如,考虑一个没有 arbiters 节点的三节点复制集。指定 w:2 将需要来自复制集中 primary 节点和一个 secondaries 节点确认。指定 w:3 将需要复制集中 primary 节点和两个 secondaries 节点确认。
|
|
请求确认写操作已经传播到大多数(majority,M)承载数据的投票成员节点。这里大多数(M)被计算为所有多数投票成员,但传播到承载数据的投票成员 M-number 后返回写操作确认(primary 和 secondaries 的与members[n].votes大于 0)。
例如,考虑一个复制集有 3 名投票成员,Primary-Secondary-Secondary (P-S-S) 架构。对于此复制集,M 是 2 时,写入操作必须传播到 Primary 和一个 Secondary 确认后 write concern 才返回到客户端。 从 4.2.1 版本开始,rs.status() 返回 writeMajorityCount。
写操作等同于 w: “majority” 后才确认给客户端,客户端可以与“majority” readConcern读取写入的结果。 See Acknowledgment Behavior for when |
|
请求确认该写操作已经传播到满足 settings.getLastErrorModes 定义的自定义写入关注标记的成员。 比如, see Custom Multi-Datacenter Write Concerns. See Acknowledgment Behavior for when |
{w: 1} 等 writeConcern 选项很好理解,Primary等待条件满足发送确认;但{w: “majority”}则相对复杂些,需要确认数据成功写入到大多数节点才算成功,而MongoDB的复制是通过Secondary不断拉取oplog并重放来实现的,并不是Primary主动将写入同步给Secondary,那么Primary是如何确认数据已成功写入到大多数节点的?
- Client向Primary发起请求,指定writeConcern为{w: “majority”},Primary收到请求,本地写入并记录写请求到oplog,然后等待大多数节点都同步了这条/批oplog(Secondary应用完oplog会向主报告最新进度)。
- Secondary拉取到Primary上新写入的oplog,本地重放并记录oplog。为了让Secondary能在第一时间内拉取到主上的oplog,find命令支持一个awaitData的选项,当find没有任何符合条件的文档时,并不立即返回,而是等待最多maxTimeMS(默认为2s)时间看是否有新的符合条件的数据,如果有就返回;所以当新写入oplog时,备立马能获取到新的oplog。
- Secondary上有单独的线程,当oplog的最新时间戳发生更新时,就会向Primary发送replSetUpdatePosition命令更新自己的oplog时间戳。
- 当Primary发现有足够多的节点oplog时间戳已经满足条件了,向客户端发送确认。
j 选项
该 j 选项请求确认来自 MongoDB 写入操作日志已被写入到磁盘上。
如果 j: true,请求确认在 mongod 实例下,如同指定 W:<value>,已经写入到磁盘上的日志。但 j:true 本身并不能保证写操作在复制集 primary 故障转移后数据的一致性。
更改在 3.2 版本,j:true 时,MongoDB 的只有被请求的成员人数,包括 primary 返回后,已经写入日记。先前 j: true 的 write concern 在复制集下仅要求在 primary 写入日志,而不管 w:<value> 的 write concern。
wtimeout
此选项为 write concern 指定一个时间限制,以毫秒为单位。wtimeout 仅适用于的 W 的值大于 1 的情况。
当指定 {w: <number>} 时,数据需要成功写入 number 个节点才算成功,如果写入过程中有节点故障,可能导致这个条件一直不能满足,从而一直不能向客户端发送确认结果,针对这种情况,客户端可设置 wtimeout 选项来指定超时时间,当写入过程持续超过该时间仍未结束,则认为写入失败。但 MongoDB 中不会撤消修改成功的数据。
如果不指定 wtimeout 选项,write concern 是无法实现的,写操作将无限期地阻塞。指定 wtimeout 值为 0 相当于没有 wtimeout 选项。
行为确认
单实例(Standalone)
一个独立的 mongod 实例,无论是应用在内存中写入之后或写入磁盘上的日志后,才确认写入操作。下表列出了一个独立的 mongod 和 write concerns 产生的行为:
j is unspecified |
j:true |
j:false |
|
|---|---|---|---|
w: 1 |
In memory | On-disk journal | In memory |
w: "majority" |
On-disk journal if running with journaling | On-disk journal | In memory |
复制集(Replica Sets)
指定 w 的值为复制集成员数量,必须承认成功返回前写的数量。对于每一个符合条件的复制集成员,j 选项确定在存储器施加写操作之后或写在磁盘上的日志后的构件是否确认写入。
下表列出了当成员可以根据 j 值确认写:
j is unspecified |
确认取决于 writeConcernMajorityJournalDefault 的值:
|
|---|---|
j: true |
确认需要写操作日志在磁盘上 |
j: false |
确认需要写入操作在内存 |
w: <number>
复制集的任何承载数据的成员可以进行 w:<number> 的写确认操作。
下表列出了当成员可以根据 j 值来确认写:
j is unspecified |
Acknowledgment requires writing operation in memory (j: false). |
|---|---|
j: true |
Acknowledgment requires writing operation to on-disk journal. |
j: false |
Acknowledgment requires writing operation in memory. |
当 w:0 时不返回请求确认
机制")
测试(会出现的数据丢失情况)
机制")
这里写一个循环插入 10 条数据,插入数据 {_id:10,a:i},然后把 writeConcern 设置为 0。根据上图我们可以看到 print 返回 10 条插入成功的信息,但是我们 db.test.count() 查看时只有一条数据,其余 9 条虽然没有插入成功但是也返回了正确信息(因为第一条数据 _id:10 为唯一键,再插入同样的数据就无法插入,两个 ID 不能相同)。就因为 {writeConcern:{w:0}} 导致出现异常时并没有返回错误信息给客户端。
当 w:1 时返回请求确认
机制")
测试(会出现的数据丢失情况)
机制")
当 w:1 时,就解决了 w:0 出现的问题,从上图可以看出第一条数据插入成功,其余 9 条数据都会插入失败并返回错误信息给客户端。
但是当 w:1 时 MongoDB 就会在日志写完之后返回确定信息,虽然解决了 w:0 出现的数据丢失问题,但是 w:1 时如果出现系统崩溃也会导致数据丢失,那就是在日志信息还没有刷新到磁盘的那一刻发生系统宕机,此时内存日志的确是写入成功了于是 MongoDB 就会返回确定信息。
我们可以通过 w:1,然后高速写入数据,然后通过 killall -9 mongod 来模拟系统崩溃(重启系统时要记住删除数据目录下的 mongod.lock 文件,不然启动起不来),最后检查程序写入的数据和实际插入的数据(这种情况发生几率不大)。
机制")
通过上图可以看出,数据丢失了 731 条。做上面这个实验时在执行 journaldataloss 函数时,需要开启另外一个会话用来模拟服务器宕机(killall -9 mongod)。
针对 w:1 出现的服务器宕机时数据丢失的问题可以使用 j:1 来解决,j:1 做到的是日志刷盘之后才会返回确定信息。
|
1 |
> db.test.validate(true) |
函数脚本
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
function journaldataloss(){ var count=0, start = new Date(); try{ var docs=[]; for(var i=0;i<1000;i++) docs.push({a:i}); while(true){ var res=db.test.insert(docs); count += res.nInserted; if(count % 100000 == 0) print("inserted "+ count+"time used: " + (new Date().getTime() - start.getTime()/1000) +" seconds"); } } catch(error){ print("Total doc inserted successfully:"+ count); } } |
当 j:1 时 Journal
机制")
实例(测试会出现的数据丢失情况)
机制")
另一种情况
机制")
当 j:1 时可以解决 w:1 数据丢失的问题,但是随之而来的是 MongoDB 的性能会下降。虽然解决了服务器宕机时数据丢失问题(会丢失 60s 左右的数据,就是一次间隔没有刷新到磁盘的数据)。但是无法解决另外一种情况,无论是 w:1 还是 j:1 都无法解决主备置换导致数据丢失的情况。
上面我们介绍了 MongoDB 三种部署模式以及每一种模式的写操作流程,看下面这幅图。
机制")
当 j:1 时可以保证主节点数据的决定安全性,当日志落盘之后返回确定信息给客户端,那么接下来就会复制 OPLOG 到复制集中的从节点如果此时主节点宕机,OPLOG 没有复制到从节点并且当主节点宕机后,MongoDB 复制集会重新选举台 secondary 为 primary。当 secondary 为 primary 后假设此时原先的 primary 被恢复了,启动之后成为了 secondary 节点,此时新的 primary 发现 secondary 有 x 数据而自己没有,那么此时就会出现数据回滚的情况,secondary 会把 x 数据进行回滚到一个磁盘文件上(rollback_db_name),回头需要人工去处理,从用户角度出现这也是一种数据丢失的情况。那么怎么解决这种情况呢?就是下面我们要提到的 w:2/N/majority 可以解决这个数据丢失的情况,w:2 决定了数据必须复制最少到一个从节点上时才会返回确定信息给客户端。
当 w:2/N/majority 时保证复制集数据一致并返回请求确认
机制")
显然这种方式虽然保证了数据的一致性,但是无疑会拖慢 MongoDB 的性能。所以在 MongoDB 3.2 后官方又给出了一个 readconcern 机制,具体待研究。
Write concern 总结
通过上面几幅图对 Write concern 的解释可以看出,这是一个对数据安全非常重要的参数,不管是开发还是运维人员都应该对 Write concern 机制非常了解。对于 Write concern 来说,级别越高数据越安全,但同时性能就会下降,在数据安全跟性能方面一向如此不能兼得。可根据自己的应用场景来决定 Write concern 的级别(默认是 w:1)。其实 j:1 到不是特别重要,如果你使用复制集,同时数据又特别重要的话就可以使用 w: majority,因为 MongoDB 中复制集的数据往往比日志跑的更快,也是一种更有效的方法。
下图是对 wirte concern 的基本总结。
机制")